février 2026
Nous sommes quatre étudiants en dernière année d’ingénierie informatique à Polytech Nice Sophia, spécialisés dans l’architecture logicielle et l’ingénierie logicielle durable.
Ce chapitre présente notre étude de la maintenabilité sur les projets de dataforgoodfr. Nous étudierons celle-ci à travers deux axes : la qualité des tests et la qualité de la documentation. Ces deux axes sont primordiaux pour assurer la qualité et donc la continuité d’un projet.
Nous avons choisi de réaliser une étude exploratoire à cause de limitations qui seront approfondies plus loin dans ce document. Celles-ci nous ont notamment poussés à faire une analyse manuelle des dépôts de code. Notre objectif principal sera donc la production d’hypothèses préalable à l’étude confirmatoire qui pourrait être réalisée dans la continuité de notre travail.
Nous analyserons les deux axes mentionnés en nous interrogeant sur les critères qui peuvent les impacter, dans le but de proposer des recommandations visant à aider les développeurs de projets à améliorer la qualité de leur test et la qualité de leur documentation.
Nous nous sommes donc fixé la problématique suivante :
Comment varie la qualité de tests & de la documentation du code dans les projets de Data For Good ?
Le premier critère de variation auquel nous avons pensé, dû à notre domaine d’étude et à la tendance du moment, est l’IA générative. Celle-ci est, depuis plusieurs années, capable d’écrire du texte, notamment du code et de la documentation, dont la qualité ne cesse de croître. Nous pensons donc que son émergence peut avoir un impact sur nos deux axes d’étude : la qualité des tests et la qualité de la documentation.
Le deuxième critère repose sur la nature de l’organisation dataforgoodfr qui met en avant la collaboration entre développeurs. Nous sommes donc en position de nous demander si l’identité des développeurs contribuant à chaque projet a un impact sur nos axes d’analyse. Malheureusement, nous sommes limités techniquement car il est difficile, voire impossible, de connaître le niveau ou l’expérience de n’importe quel contributeur dans n’importe quel domaine. Nous sommes donc retourné vers un critère plus concret et plus simple : le nombre de contributeurs. En effet, il nous semble naturel qu’un projet réunissant de nombreux individus sera mieux documenté pour assurer la collaboration qu’un projet développé par un seul ou deux contributeurs. Ce sera donc notre deuxième critère d’étude.
Enfin, en explorant les projets de dataforgoodfr, nous avons remarqué que de nombreux projets étaient liés à l’IA (comme outil). Nous avons donc souhaité nous pencher sur ce cas particulier, en comparant les projets AI-related et ceux non AI-related.
Nous répondrons donc aux questions suivantes :
- L’entrée de l’IA générative dans le quotidien a-t-elle eu un impact dans ces deux domaines ?
- Quel impact le nombre de collaborateurs a-t-il sur la qualité des tests et la documentation ?
- Quelles différences de qualité de tests sont présentes entre les projets incluant des composants d’IA et les autres ?
Les dépôts à analyser ont été choisis de manière aléatoire tout en s’assurant d’avoir un projet par triplet de catégorie : réalisation par rapport à la sortie publique de l’IA générative, nombre de collaborateurs, lien avec des composants d’IA.
La première question cherche à étudier l’impact de l’IA générative sur les projets de dataforgoodfr. À défaut de pouvoir analyser précisément quels projets ont utilisé de tels outils, nous nous sommes basés pour cette étude sur la capacité des développeurs à utiliser l’IA générative. En nous basant sur la courbe trends.google.com des termes “chatgpt”, “chat gpt” et “gpt” disponible ci-dessous. Ces termes concernent tous l’outil leader de l’IA générative ChatGPT.com.
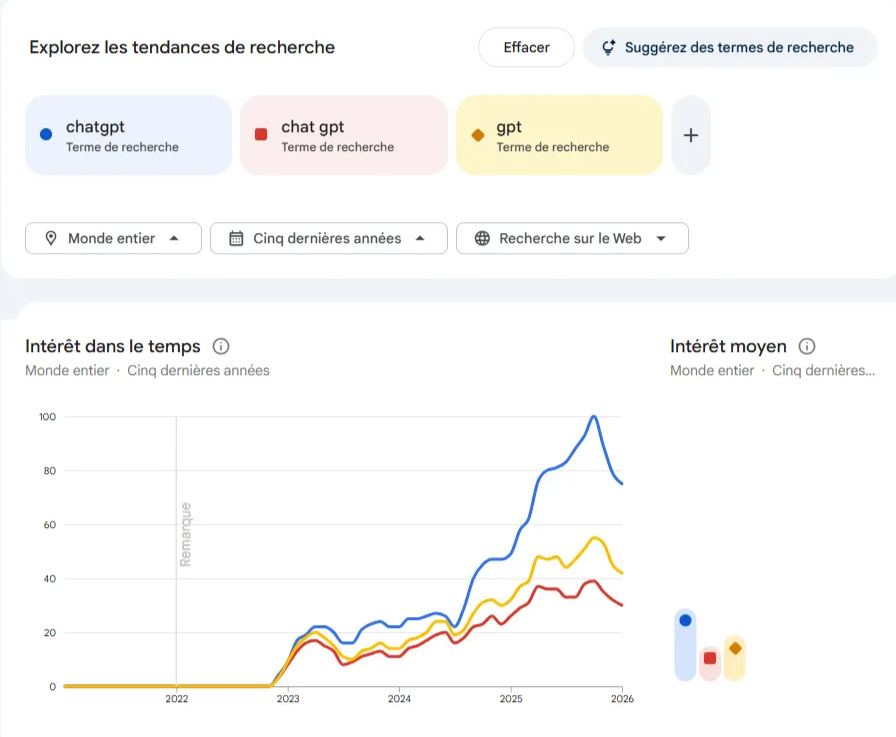
Celle-ci met en évidence deux dates : novembre 2022, date de publication du site ChatGPT.com et août 2024 qui semble correspondre à une nouvelle hausse d’utilisation de la plateforme. Ces dates, par extension, indiquent les phases qu’a connues l’IA générative : avant l’entrée dans le quotidien de la GenAI, pendant cette entrée et après l’admission à grande échelle de cette technologie.
Après vérification de la répartition de l’ensemble des projets de dataforgoodfr, nous avons pu observer que leurs dates d’activités sont quasiment réparties avec un tiers des projets avant l’émergence de l’IA générative, un tiers pendant son émergence et un dernier tiers après celle-ci. Cette répartition justifie ainsi de prendre le même nombre de projets pour chacune de ses catégories dans notre échantillon.
La deuxième question permet de se pencher sur l’impact du nombre de contributeurs sur les projets. Nous avons développé un script python (analyse_number_of_contributors.py) qui nous a permis de calculer des statistiques sur le nombre de contributeurs des projets de l’organisation dataforgoodfr. Les résultats sont présents ci-dessous.
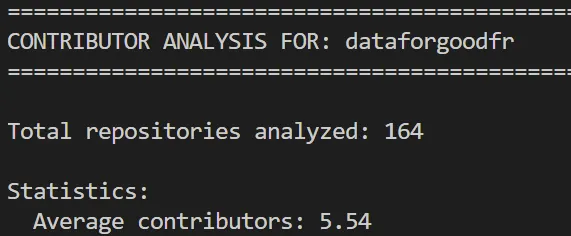
On peut voir que la moyenne du nombre de contributeurs sur un dépôt est de 5.54. Nous considérons donc les projets ayant cinq contributeurs ou moins comme des petits projets et ceux ayant six ou plus comme des gros projets.
La dernière question concerne la proximité du projet avec des composants d’IA. Les dépôts peuvent ainsi être AI-related ou ne pas l’être. Sont définis comme en rapport avec l’IA les projets permettant d’entraîner des réseaux de neurones, ceux utilisant des APIs d’IA, ou encore ceux qui concernent des RAGs.
Ainsi, nous avons choisi 12 dépôts, car chaque projet peut :
Nous aurons donc 4 projets par catégorie de la question 1, 6 par catégorie de la question 2 et 6 par catégorie de la question 3.
| Peu de contributeurs | Beaucoup de contributeurs | |
|---|---|---|
| AI-related | offseason_missiontransition_categorisation | batch4_diafoirus_fleming |
| Non AI-related | website2022 | batch5_phenix_happymeal |
| Peu de contributeurs | Beaucoup de contributeurs | |
|---|---|---|
| AI-related | batch11_cartovegetation | bechdelai |
| Non AI-related | protectclimateactivists | offseason_ogre |
| Peu de contributeurs | Beaucoup de contributeurs | |
|---|---|---|
| AI-related | 13_ia_financement | 13_democratiser_sobriete |
| Non AI-related | 14_PrixChangementClimatique | shiftdataportal |
Nous pensons que l’émergence de l’IA générative va conduire à des projets mieux documentés et mieux testés. L’efficacité des LLMs à la réalisation de ces tâches a déjà été démontrée, notamment par Karlsson, Daniel, et Abraham dans “ChatGPT: A gateway to AI generated unit testing.” et par Cui, Xing, et al. dans “RMGenie: An LLM-Based Agent Framework for Open Source Software README Generation.”.
Il nous semble naturel que les projets avec un grand nombre de contributeurs seront à la fois mieux testés et mieux documentés pour assurer le bon travail d’équipe des nombreux collaborateurs.
Nous pensons que les projets AI-related seront moins bien testés que les autres à cause de la complexité existante pour produire des tests pour des réseaux de neurones ou des RAGs.
Chaque projet est noté selon la qualité de sa notation et selon la qualité de ses tests. Nous sommes quatre jurys, nous utiliserons tous les quatre les mêmes grilles de notation décrite ci-dessous.
Afin d’assurer la qualité des notes et la reproductibilité de notre protocole, nous avons fixé ensemble des définitions claires et précises de nos axes d’études : la qualité des tests et la qualité de la documentation.
Critères de la qualité de la documentation
Critères de la qualité de tests
Une fois les définitions fixées, nous avons attribué un nombre de points maximal à chacun des critères en fonction de leur importance et la profondeur attendue en nous basant sur nos avis de futurs ingénieurs logiciels.
Barème de la qualité de la documentation
| Critère | Coefficient |
|---|---|
| README description fonctionnelle du projet | 25 |
| README Explication architecture technique | 20 |
| README instruction installation | 25 |
| README nom et contact des contributeurs | 5 |
| CHANGELOG à jour | 10 |
| CONTRIBUTING complet | 10 |
| LICENCE présente | 5 |
Barème de la qualité des tests
| Critères | Coefficient |
|---|---|
| Présence de tests | 15 |
| Niveaux présents (UT/IT/E2E) | 25 |
| Qualité des tests | 25 |
| Coverage dispo + couverture | 25 |
| Entretien dans le temps (Git) | 10 |
Une fois chaque projet noté par chaque jury selon les critères définis, nous avons pu construire les tableaux récapitulatifs de nos notes brutes (all.csv).
À partir des fichiers mentionnés ci-dessus, nous avons calculé et agrégé les moyennes des jurys afin d’obtenir, pour chaque projet, une note de qualité des tests et de la documentation. Dans un même temps, nous avons calculé le coefficient de corrélation intraclasse de chaque projet pour chaque axe ainsi que son interprétation selon la table n°7 du papier de HAN, Xiaoxia. “On statistical measures for data quality evaluation. Journal of Geographic Information System, 2020, vol. 12, no 3, p. 178-187.”. Ce coefficient nous permet de mesurer l’accord entre les notations des jurys. Nous avons donc développé un script python (statistiques_par_projet.py), qui traite les quatre fichiers CSV de notation de chaque jury pour générer un csv présenté dans le tableau suivant.
| Projet | Moyenne test | ICC test | Interprétation ICC test | Moyenne doc | ICC doc | Interprétation ICC doc |
|---|---|---|---|---|---|---|
| 13_ia_financement | 11.5 | 0.245 | poor | 79.5 | 0.83 | good |
| 13_democratiser_sobriete | 52.5 | 0.8 | good | 66.25 | 0.731 | moderate |
| offseason_missiontransition_categorisation | 30.75 | 0.749 | moderate | 63.75 | 0.959 | excellent |
| shiftdataportal | 36.0 | 0.869 | good | 41.0 | 0.765 | good |
| batch4_diafoirus_fleming | 0.5 | 0.333 | poor | 25.25 | 0.925 | excellent |
| website2022 | 5.75 | -0.263 | poor | 62.5 | 0.832 | good |
| batch5_phenix_happymeal | 31.5 | 0.808 | good | 53.5 | 0.77 | good |
| batch11_cartovegetation | 0.75 | 0.267 | poor | 53.25 | 0.932 | excellent |
| bechdelai | 45.25 | 0.818 | good | 69.0 | 0.843 | good |
| protectclimateactivists | 0.75 | 0.267 | poor | 30.25 | 0.851 | good |
| offseason_ogre | 23.25 | 0.172 | poor | 67.25 | 0.864 | good |
| 14_PrixChangementClimatique | 0.75 | 0.267 | poor | 29.75 | 0.832 | good |
À partir de ces données traitées, nous avons groupé les projets selon les différentes catégories afin de tenter de répondre à chacune des trois sous-questions pour produire nos résultats.
Comme mentionné dans l’introduction, nous n’avons pas pu analyser l’intégralité des dépôts pour produire des conclusions visant l’ensemble des projets de Data For Good France par manque de temps dans le cadre de cette étude. Plusieurs aspects de notre méthodologie doivent être automatisés pour atteindre un tel but :
Nous avons choisi pour notre étude de catégoriser les projets étudiés selon chacune de nos sous-questions (par date, par tailles, par nature). Il pourrait être intéressant, si l’ensemble des dépôts est analysé de faire des analyses de manières plus continues, sans catégoriser les projets. Il serait ainsi possible d’avoir l’évolution de la qualité de la documentation dans le temps, mises en perspective par les dates clé de l’IA générative que nous avons identifié, ou de trouver le nombre de contributeurs idéal dans un dépôt pour espérer obtenir les tests les plus qualitatifs possibles. En résumé, s’abstraire des catégories (avant/pendant/après GenAI, peu/beaucoup de contributeurs et AI-related/non AI-related) ouvrirait la porte à des analyses plus précises.
Afin d’évaluer la fiabilité des notations produites par les quatre membres du jury, nous avons calculé, pour chaque projet et pour chacun des deux axes (tests et documentation), un coefficient de corrélation intraclasse (ICC). Comme expliqué précédemment.
Lors de la première itération de notation, nous avons observé pour plusieurs projets des valeurs d’ICC faibles, montrant un désaccord important entre les jurys. Cette situation nous a amenés à discuter nos résultats collectivement afin d’identifier les sources de divergence dans l’interprétation des critères de la grille de notation.
À l’issue de ces échanges, certaines ambiguïtés ont été mises en évidence, notamment :
Nous avons alors procédé à une seconde itération de notation, en conservant les mêmes critères et barèmes, mais avec une compréhension partagée plus précise de ceux-ci. Toutefois, cette nouvelle itération a également révélé l’arrivée de nouvelles problématiques d’interprétation, notamment liées à l’hétérogénéité des projets analysés (langages, objectifs, contraintes techniques).
En conséquence, malgré ces itérations successives, certains projets présentent encore des ICC faibles, en particulier pour l’axe qualité des tests. Cela montre à la fois :
Pour mieux comprendre les divergences dans les notations, nous avons analysé statistiquement les désaccords entre les quatre juges à l’aide d’un script Python (analyse_desaccords_juges.py).
L’analyse révèle des différences notables de sévérité entre les juges :
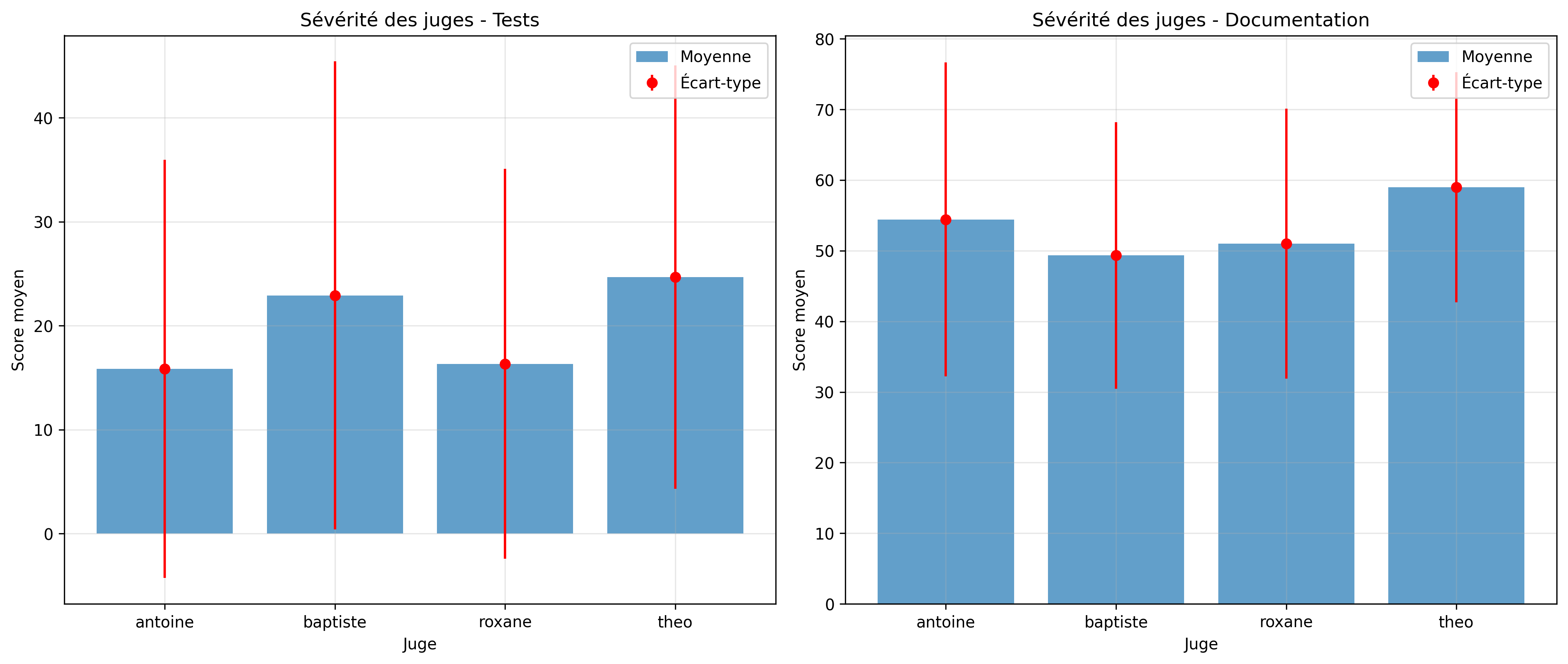
L’analyse des différences entre paires de juges montre que :
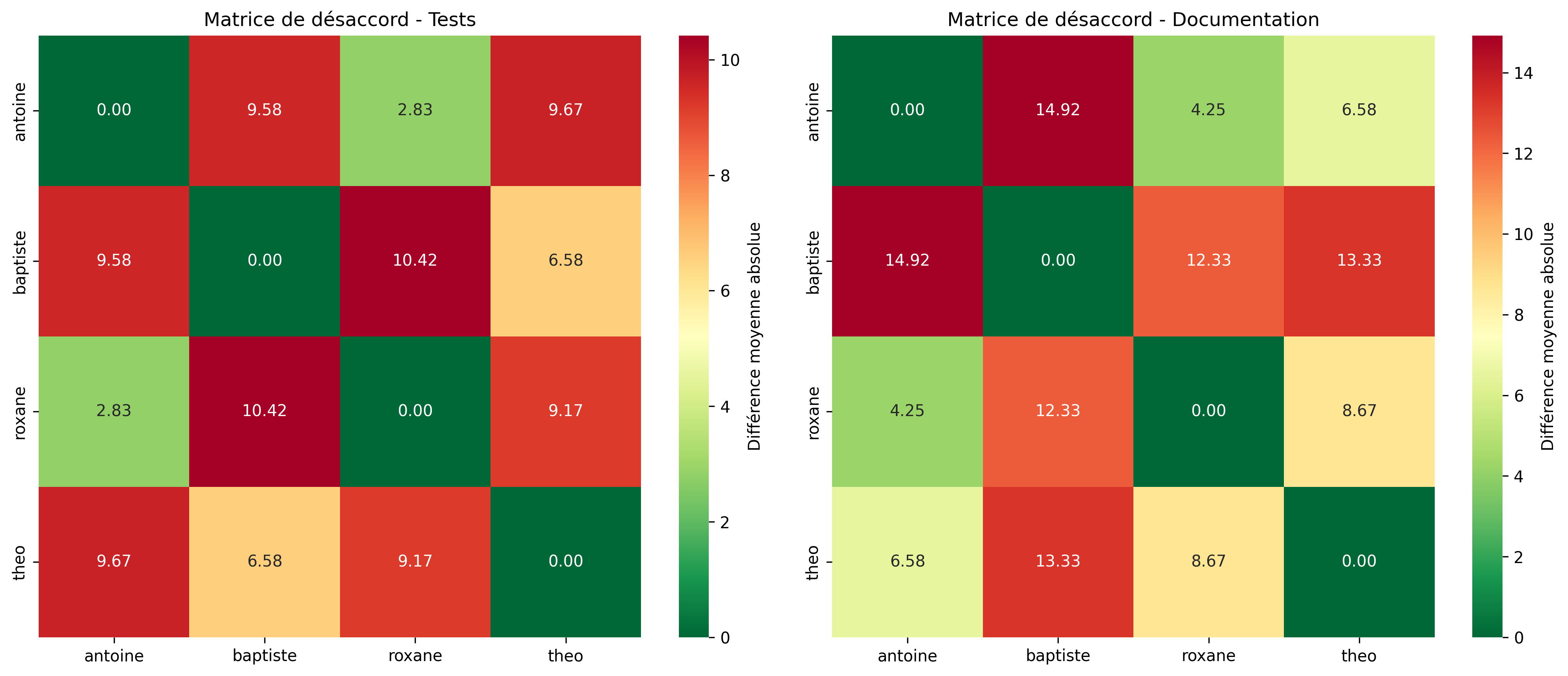
Certains projets ont généré des désaccords importants, notamment :
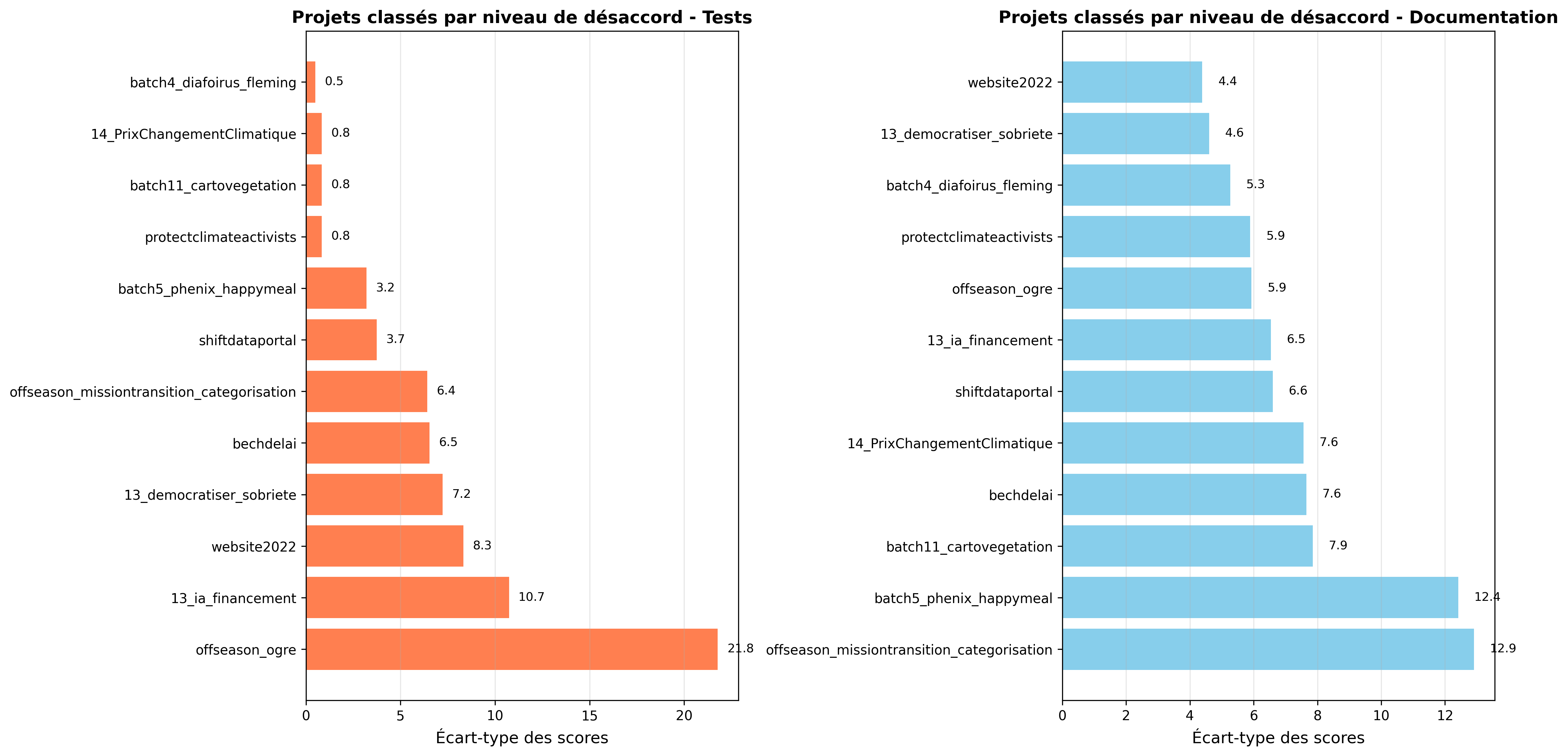
Ces désaccords s’expliquent principalement par des interprétations différentes sur :
Malgré une grille commune et des calibrations, une part de subjectivité persiste. Le bon accord entre certaines paires de juges et les ICC acceptables pour la documentation valident néanmoins la robustesse globale de la méthodologie. Pour améliorer la reproductibilité future, l’automatisation partielle de l’évaluation des tests serait bénéfique.
L’ensemble des notes brutes est disponible ici : all.csv (toutes agrégées), ou ici : 1_notes_per_judge (notes juge par juge).
Les notes moyennes de chaque dépôt ont été calculées et sont disponibles ici : statistiques_par_projet.csv
Comme le montre le résultat produit par notre script, la qualité de la documentation sur les 12 dépôts analysés reste
constante quel que soit le niveau d’émergence la GenAI, par contre la qualité de test semble croître avec celle ci.
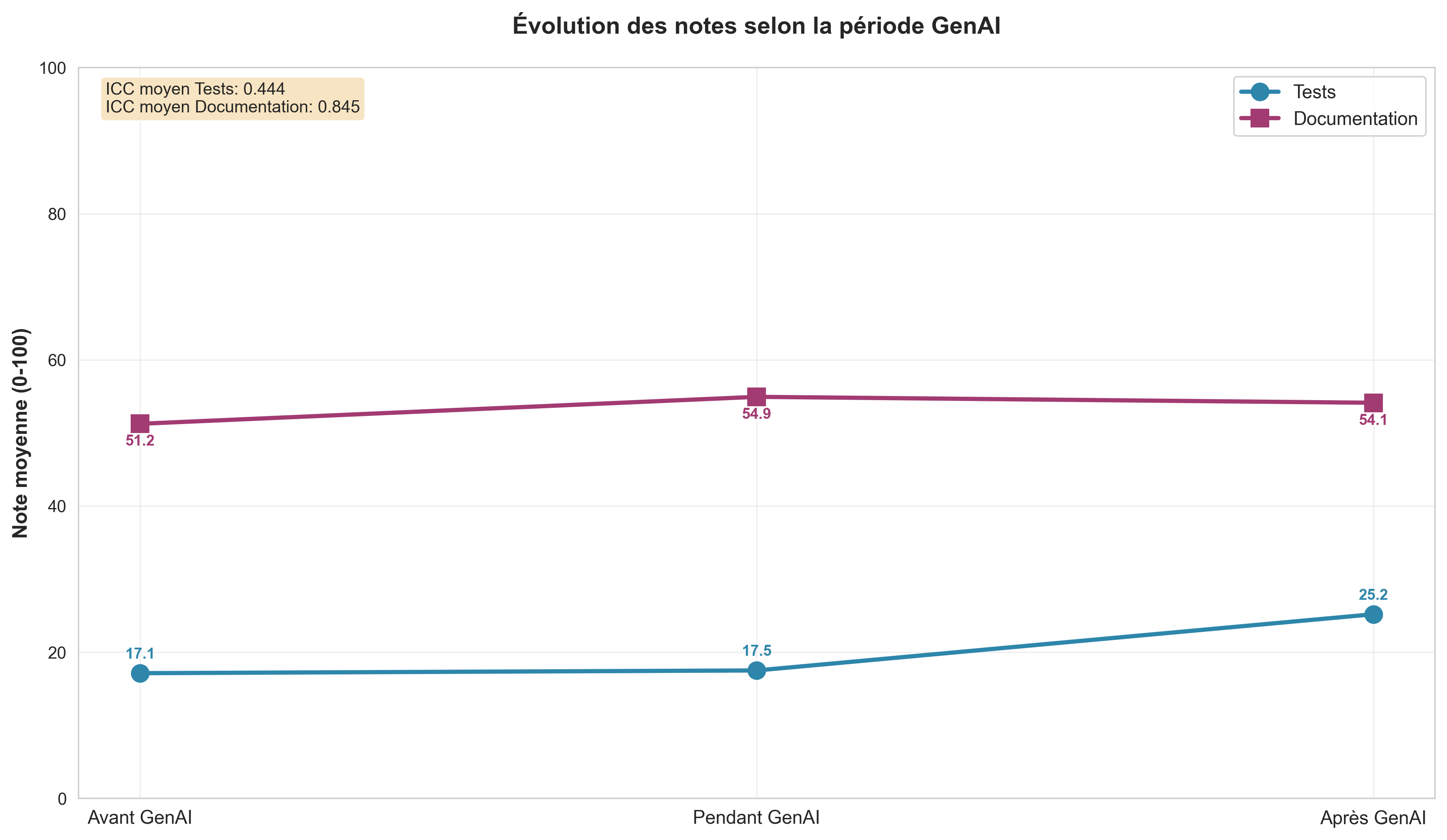
Sur l’ensemble des 166 projets, nous nous attendons à un maintien du niveau moyen de la qualité de la documentation quelle que soit la date d’activité de dépôt et à une amélioration de la qualité après l’entrée dans le quotidien de l’IA générative.
Comme le montre le résultat produit par notre script, la qualité de la documentation sur les 12 dépôts analysés ne
semble pas impactée par le nombre de collaborateurs. Sur ce même échantillon, la qualité des tests est par contre
grandement amélioré (multiplié par 3.5)
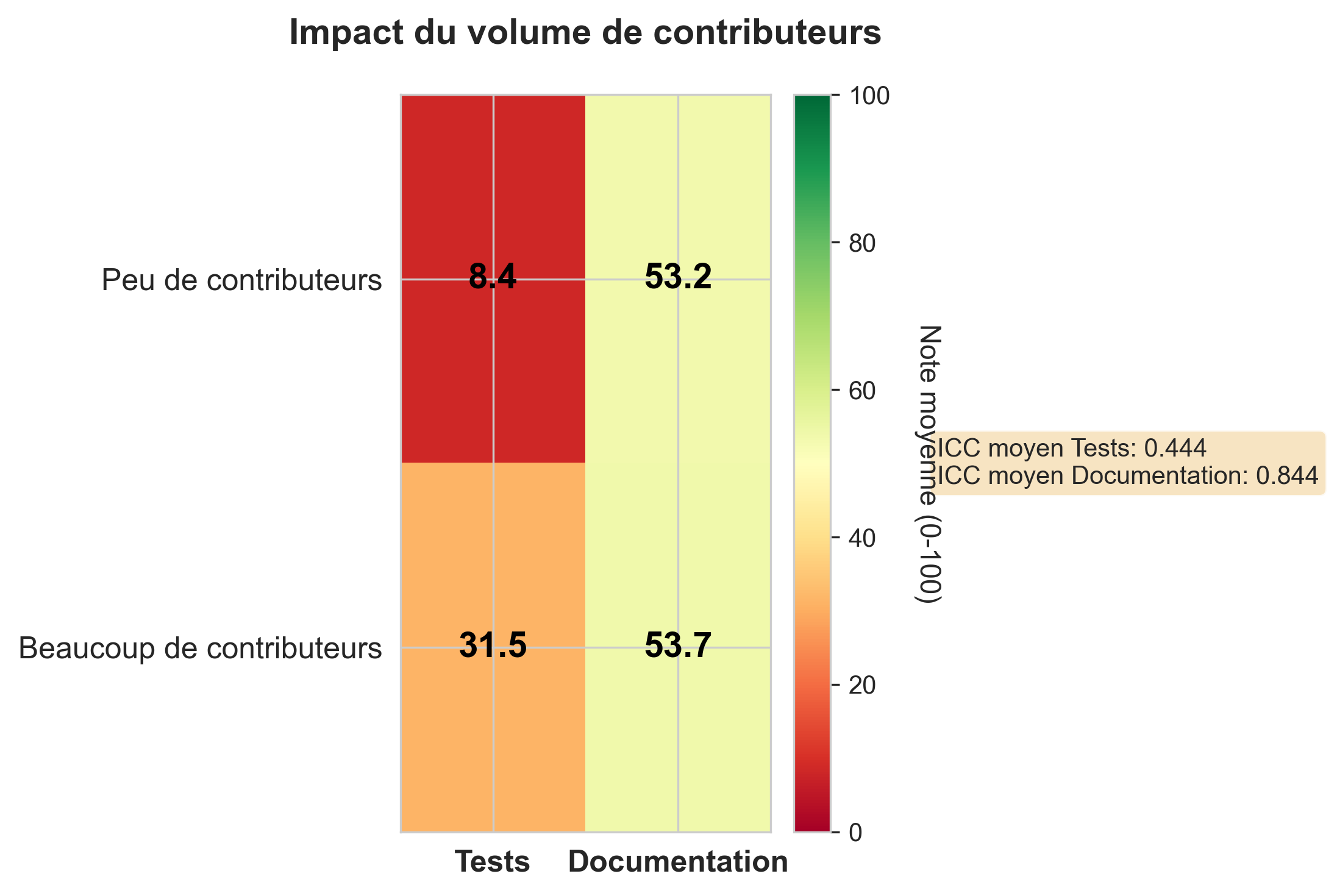
Sur l’ensemble des 166 projets, nous nous attendons à un maintien du niveau moyen de la qualité de la documentation quelle que soit la date d’activité de dépôt et à une meilleure qualité des tests pour les projets avec un nombre important de contributeurs.
Comme le montre le résultat produit par notre script, sur les 12 dépôts analysés la qualité de la documentation et la
qualité des tests semblent légèrement meilleures sur les projets AI-related que sur les autres.
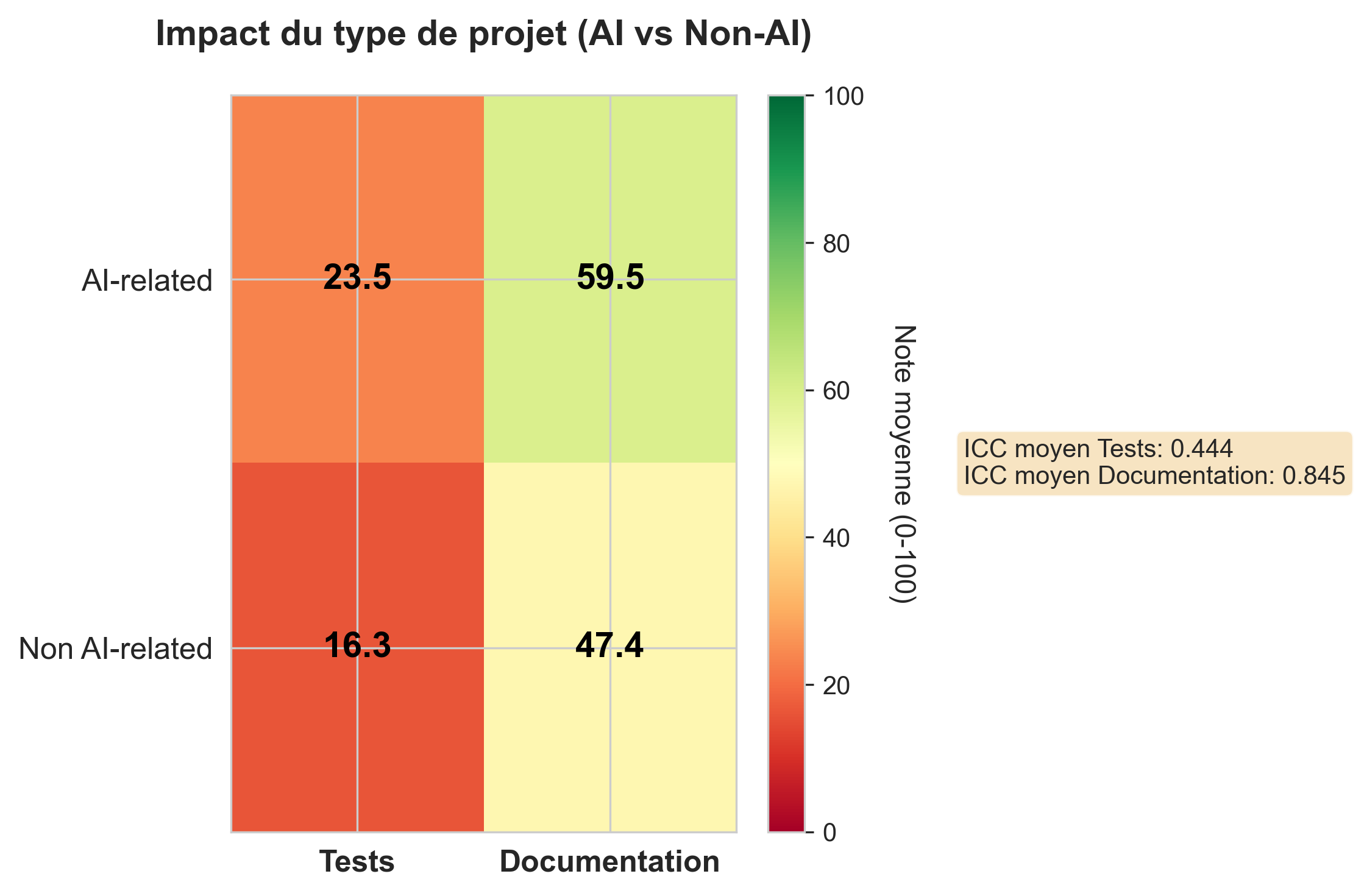
Sur l’ensemble des 166 projets, nous nous attendons à ce que les projets AI-related soient probablement un peu mieux documentés et légèrement mieux testés que les autres.
L’entrée de l’IA générative dans le quotidien et le grand nombre de contributeurs semblent avoir un impact positif sur la qualité des tests, mais pas forcément sur la documentation.
Les projets AI-related semblent avoir des tests et une documentation légèrement plus qualitative que les autres.
Ce script nous a permis de calculer la médiane du nombre de contributeurs par dépôt pour ensuite classifier ceux ciblés par notre étude parmi “peu de contributeurs” ou beaucoup de contributeurs”
Il requiert l’utilisation d’un Personnal Access Token Github pour éviter le rate limiting de la plateforme.
Ce fichier n’est pas primordial, il nous a permis de convertir le seul fichier CSV (extrait depuis une base de donnée Notion dans laquelle nous avons rassemblé nos notes) qui incluait les notes de tous les jurys en quatre fichiers CSV pour en avoir un par jury et ainsi simplifier les traitements ultérieurs.
Ce fichier est le premier des deux principaux ayant permis de faire nos analyses. C’est celui qui nous a permis d’agréger et de moyenner l’ensemble des notations. Il parcourt les quatre fichiers de notation des jurys pour faire la somme du nombre de points par chaque axe et par projet de chaque jury avant de calculer la note moyenne, ainsi que son ICC et son interprétation par axe par projet pour générer un fichier CSV récapitulatif.
Ce dernier fichier est le deuxième fichier d’analyse principal. Il permet de traiter concrètement le fichier récapitulatif en groupant les projets par catégories pour chacune de nos questions à l’aide du fichier mapping_projet.csv. Celui permet de générer l’ensemble des fichiers de résultats (infographies et résultats bruts) présents dans le dossier 3_analysis :
La matrice de qualité des axes d’étude selon la nature AI-related du projet (AI-related/non AI-related).
Ce script est dédié à l’analyse des désaccords entre les membres du jury. Il permet notamment :
de produire des visualisations synthétiques (graphiques de sévérité, matrices de désaccords, classements des projets).
Ce script génère des visualisations détaillées, projet par projet, des notations attribuées par chaque juge. Il propose une représentation, incluant :
Site web: DataForGood
Fiallos Karlsson, Daniel, and Philip Abraham. ChatGPT: A gateway to AI generated unit testing. ( 2023).
Cui, Xing, et al. RMGenie: An LLM-Based Agent Framework for Open Source Software README Generation. 2025 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 2025.
Han, Xiaoxia. On statistical measures for data quality evaluation.” Journal of Geographic Information System” 12.3 ( 2020): 178-187.