Auteur : Sacha Chantoiseau · sacha.chantoiseau@etu.univ-cotedazur.fr
Cette section explique comment régénérer tous les graphiques et résultats présentés dans ce chapitre à partir des scripts fournis.
cd zero-to-hero/assets/scripts
pip install -r requirements.txt
playwright install chromium
Les scripts de scraping ont besoin d’une session authentifiée sur Kaggle. Le fichier kaggle_state.json stocke cette session (cookies Playwright).
python 02_login_save_state.py
Ce script ouvre un navigateur Chromium. Connectez-vous manuellement sur Kaggle, puis le script sauvegarde la session dans kaggle_state.json.
Sécurité : Ce fichier contient vos cookies de session. Il est listé dans le
.gitignoreet ne doit jamais être commité. Si vous clonez le dépôt, vous devez le régénérer vous-même.
Les expériences 5 et 7 utilisent des leaderboards téléchargés manuellement depuis Kaggle (cette étape ne peut pas être automatisée car Kaggle ne fournit pas d’API de téléchargement pour les leaderboards) :
https://www.kaggle.com/competitions/optiver-trading-at-the-close/leaderboardout/leaderboards/Le nom du ZIP doit correspondre au slug de la compétition (partie de l’URL après /competitions/).
Les 8 compétitions utilisées dans notre analyse sont :
optiver-trading-at-the-close (4 436 équipes)jane-street-market-prediction (4 245 équipes)jane-street-real-time-market-data-forecasting (3 757 équipes)predict-energy-behavior-of-prosumers (2 731 équipes)cmi-detect-behavior-with-sensor-data (2 657 équipes)asl-signs (1 165 équipes)llm-prompt-recovery (2 175 équipes)santa-2024 (1 514 équipes)bash reproduce.sh
Ce script exécute les 7 expériences dans l’ordre, génère les 10 graphiques dans out/figures_sq1/, puis les copie dans assets/images/ pour le rendu du chapitre.
| Étape | Automatisé | Manuel |
|---|---|---|
| Scraping des profils et leaderboards Kaggle | Oui (Playwright) | Non |
| Authentification Kaggle | Semi — le script ouvre le navigateur, l’utilisateur se connecte | Connexion manuelle |
| Téléchargement des leaderboards (ZIP) | Non — pas d’API disponible | Oui, bouton Download sur Kaggle |
| Calcul des métriques et génération des graphiques | Oui (Python) | Non |
| Sélection des compétiteurs étudiés | Non — choix expliqué dans la méthodologie | Oui, sélection raisonnée |
.gitignoreLe fichier .gitignore à la racine de zero-to-hero/ exclut :
kaggle_state.json # Session Kaggle (sensible, à régénérer)
out/ # Données et graphiques (régénérés par reproduce.sh)
__pycache__/ # Cache Python
*.pyc # Bytecode Python
Guide complet : Consultez
assets/scripts/README.mdpour le dépannage et les détails de chaque étape.
Kaggle est la plateforme de référence mondiale pour les compétitions de data science, rassemblant plus de 201 000 compétiteurs classés (source : page rankings, janvier 2026). Le classement global (rankings) reflète les performances cumulées de chaque participant à travers des centaines de compétitions couvrant des domaines très variés : vision par ordinateur, NLP, séries temporelles, optimisation combinatoire, etc.
Le système de points Kaggle fonctionne de manière cumulative : chaque médaille d’or, d’argent ou de bronze obtenue dans une compétition rapporte des points, et le classement reflète le total accumulé. Cela signifie qu’un compétiteur peut progresser au classement de deux façons : en obtenant de meilleurs résultats dans chaque compétition, ou en participant à davantage de compétitions.
Un cas particulier a attiré notre attention : yuanzhezhou, actuellement classé #1 mondial sur 201 348, a connu une progression fulgurante, passant du top 300 au top 1 en moins de 3 ans. Là où la plupart des compétiteurs progressent graduellement sur 5 à 10 ans, cette trajectoire est exceptionnellement rapide. Son profil affiche 87 compétitions terminées, 14 médailles d’or, 15 d’argent et 11 de bronze.
L’intuition première pour expliquer une telle progression serait d’invoquer un “saut technique” : meilleurs modèles, meilleur feature engineering, accès à plus de GPU. Cependant, ces facteurs sont difficiles à mesurer de l’extérieur : le code des compétitions est rarement rendu public, et même les write-ups des gagnants ne révèlent pas tout.
Nous choisissons donc d’investiguer des facteurs observables et mesurables depuis les données publiques de Kaggle : le volume d’activité et les pratiques de collaboration. Notre question de recherche est :
La progression du #1 mondial s’explique-t-elle principalement par une intensification de l’activité et une stratégie de collaboration, plutôt que par des facteurs purement techniques ?
Notre analyse repose sur trois sources de données, toutes issues de la plateforme Kaggle :
Profils publics des compétiteurs : accessibles via kaggle.com/<username>, ils affichent l’historique complet des compétitions (rang obtenu, nombre d’équipes, date approximative). Ces données sont extraites par web scraping automatisé (voir section 3 pour la justification de cette méthode).
Leaderboards de compétitions : chaque compétition Kaggle publie un leaderboard contenant, pour chaque participant : son rang, le nom de son équipe, et la liste des membres (colonne TeamMemberUserNames). Ces leaderboards sont téléchargeables en fichiers ZIP depuis l’interface web de Kaggle. Nous avons téléchargé manuellement 8 leaderboards de compétitions majeures, totalisant 19 897 lignes (participants) après agrégation.
Rangs globaux des compétiteurs : la page de profil de chaque utilisateur affiche son rang global (“X of 201,348”). Nous les avons extraits par scraping pour les 23 coéquipiers de yuanzhezhou et les 75 coéquipiers des fast risers étudiés.
Le compétiteur a augmenté significativement le nombre de compétitions auxquelles il participe chaque année.
Pourquoi cette hypothèse ? Le système de points Kaggle est cumulatif : plus un compétiteur participe à des compétitions et y obtient de bons résultats, plus il accumule de points. Il est donc mathématiquement avantageux de participer à un grand nombre de compétitions plutôt que de se concentrer sur une seule. À niveau de performance constant, un doublement du nombre de compétitions par an peut mécaniquement doubler le potentiel de points accumulés. C’est l’hypothèse la plus simple et la plus directement vérifiable : le volume d’activité a-t-il changé ?
Le compétiteur est passé de participations majoritairement solo à des participations en équipe avec des coéquipiers déjà très bien classés au niveau global.
Pourquoi cette hypothèse ? Sur Kaggle, les compétitions permettent de former des équipes de 2 à 5 membres. Travailler en équipe offre plusieurs avantages documentés dans la communauté Kaggle : division du travail (un membre fait le feature engineering, un autre l’entraînement), diversité des approches (chaque membre essaie une architecture différente), et surtout ensembling de modèles (la moyenne de N modèles indépendants est souvent meilleure que chaque modèle seul). De plus, s’associer avec des compétiteurs déjà expérimentés (GrandMasters, Masters) augmente les chances de podium car ils apportent un savoir-faire éprouvé. Nous soupçonnons que le basculement solo vers équipe est un facteur clé de la progression de yuanzhezhou.
Le compétiteur adopte une rotation fréquente de coéquipiers, ce qui lui permet de participer à un grand nombre de compétitions en parallèle.
Pourquoi cette hypothèse ? Les règles Kaggle limitent la participation d’un même individu à une seule équipe par compétition, mais n’empêchent pas de changer de coéquipiers d’une compétition à l’autre. Un compétiteur qui forme une équipe différente pour chaque compétition n’est limité par la disponibilité de personne : si le coéquipier A est occupé sur la compétition X, on peut former une équipe avec le coéquipier B sur la compétition Y. Cette stratégie de “rotation” pourrait être un levier stratégique majeur pour enchaîner les podiums et maximiser le volume de participations simultanées.
La “force Kaggle” moyenne des coéquipiers (rang global moyen) est corrélée aux performances obtenues.
Pourquoi cette hypothèse ? Si la collaboration est un facteur, alors la qualité des coéquipiers devrait aussi compter. Un coéquipier classé top 50 mondial apporte probablement plus de valeur technique qu’un coéquipier classé top 5 000 : plus d’expérience en compétition, meilleure maîtrise des techniques d’ensembling, connaissance des pièges classiques. Nous voulons vérifier que yuanzhezhou ne s’associe pas avec n’importe qui, mais sélectionne des partenaires de haut niveau, et que cette sélection est corrélée à la performance obtenue.
Pour éviter de construire un récit ad hoc autour d’un seul individu (ce qui constituerait un biais de sélection majeur), nous vérifierons si ces patterns se retrouvent :
Dans plusieurs compétitions majeures (Exp. 5) : Les participants en équipe sont-ils sur-représentés dans le haut du leaderboard par rapport aux solos ? Nous utilisons pour cela 8 leaderboards de compétitions récentes et variées (finance, biologie, NLP, optimisation), totalisant 19 897 participants. Si les équipes performent mieux en moyenne, cela confirme que la collaboration est structurellement avantageuse, indépendamment de l’individu étudié.
Chez d’autres “fast risers” (Exp. 6) : Nous avons identifié 5 autres compétiteurs qui, comme yuanzhezhou, figurent dans le top 25 mondial et ont connu une progression rapide dans les dernières années : jsday96, daiwakun, tomoon33, HarshitSheoran, sayoulala. Le choix de ces 5 compétiteurs repose sur l’observation de leurs positions actuelles dans le top 25 et de la date de leurs premières compétitions (tous actifs depuis moins de 5 ans avec une progression notable). Si le pattern d’intensification de la collaboration est récurrent chez ces “fast risers”, ce n’est pas une coïncidence propre à yuanzhezhou.
Dans le top 25 global (Exp. 7) : Les 24 meilleurs compétiteurs mondiaux (au moment de la collecte) sont analysés pour situer la stratégie de yuanzhezhou dans le contexte global. Utilisent-ils systématiquement des équipes ? Avec un noyau fixe ou une rotation de partenaires ? Cela permet de comprendre si la diversification des collaborations est un facteur récurrent de performance durable, ou si d’autres stratégies (équipes stables, solo pur) fonctionnent aussi.
Kaggle fournit une API officielle (kaggle.com/docs/api), mais celle-ci est limitée pour notre cas d’usage :
TeamMemberUserNames)Nous avons donc opté pour un web scraping automatisé via Playwright (bibliothèque Python de contrôle de navigateur). Playwright a été choisi plutôt que Selenium ou BeautifulSoup car :
requests.get() ne renvoie qu’une page vide.kaggle_state.json), évitant de se reconnecter à chaque exécutionPour l’analyse par déciles (Exp. 5), nous avons sélectionné 8 compétitions selon les critères suivants :
Les 8 compétitions retenues totalisent 19 897 lignes (participants), avec une médiane de ~2 000 équipes par compétition.
yuanzhezhou (sujet principal) : choisi car il est le #1 mondial au moment de l’étude (janvier 2026), avec une progression documentée de ~300e à 1er en moins de 3 ans. C’est le cas le plus extrême et donc le plus intéressant à analyser.
Fast risers (Exp. 6, 6 compétiteurs) : yuanzhezhou, jsday96, daiwakun, tomoon33, HarshitSheoran, sayoulala. Ces 5 autres compétiteurs ont été sélectionnés parmi le top 25 mondial sur la base de deux critères : (1) date de première compétition récente (< 5 ans), ce qui indique une progression rapide, et (2) présence dans le top 25 au moment de la collecte. Le choix est limité à 6 utilisateurs pour des raisons pratiques : chaque utilisateur nécessite ~2 minutes de scraping (profil + leaderboards de chaque compétition + profils des coéquipiers), soit ~12 minutes de scraping rien que pour cette expérience.
Top 25 (Exp. 7, 24 compétiteurs) : les 24 premiers du classement global au moment de la collecte. Ce nombre n’est pas arbitraire : c’est la totalité du top 25 (moins 1 car un profil était inaccessible). L’objectif est d’analyser l’ensemble des meilleurs, pas un sous-échantillon.
| Métrique | Formule / Description | Utilisée dans |
|---|---|---|
nb_competitions |
Nombre de compétitions par année | Exp. 1 |
perf_score |
Score basé sur le rang relatif : top 1% = 100 pts, top 5% = 70, top 10% = 40, top 25% = 15, reste = 5 | Exp. 1, 4 |
team_size |
Nombre de membres dans l’équipe (1 = solo) | Exp. 2, 5 |
team_ratio |
Proportion de compétitions en équipe (>1 membre) | Exp. 2, 6, 7 |
unique_teammates |
Nombre de coéquipiers distincts sur la période | Exp. 3, 7 |
avg_teammate_rank |
Rang global moyen des coéquipiers | Exp. 4, 6 |
rotation |
Ratio coéquipiers uniques / compétitions en équipe (élevé = changement fréquent) | Exp. 7 |
stability |
Inverse de la rotation (élevé = mêmes coéquipiers récurrents) | Exp. 7 |
collab_index |
Indice composite (0-1) : 0.4 × team_ratio + 0.25 × unique_teammates_norm + 0.2 × strength_norm + 0.15 × nb_comp_norm |
Exp. 6 |
| Outil | Rôle |
|---|---|
| Python 3.10+ | Langage principal |
| Playwright | Scraping des pages Kaggle (rendu JavaScript, lazy loading, authentification) |
| pandas | Manipulation des données (CSV, agrégations, pivot tables) |
| matplotlib | Génération des graphiques |
| reproduce.sh | Script Bash orchestrant les 7 expériences dans l’ordre |
Chaque expérience correspond à un script Python autonome (voir annexe). Les scripts utilisent un système de cache : les données déjà scrapées ne sont pas re-téléchargées (fichiers CSV intermédiaires, teammate_global_ranks.json), ce qui rend la re-exécution rapide si les données n’ont pas changé.
Chaque hypothèse est testée par une expérience dédiée. Pour chaque expérience, nous détaillons : la question, les données, la méthode, le script utilisé, les résultats et l’analyse.
Question : Le volume de compétitions et les performances de yuanzhezhou ont-ils augmenté au fil du temps ?
Données collectées :
Méthode : Le script sq1_scrape_timeline_user.py utilise Playwright pour :
kaggle_state.json)Limite de la méthode : la date est inférée depuis “X years ago”, ce qui donne une approximation à l’année près. La date exacte de fin de compétition n’est pas accessible depuis le profil.
Données produites : out/user_competitions_raw.csv — 25 lignes, une par compétition, avec : slug, année, rang, nombre d’équipes, score de performance.
Résultat :
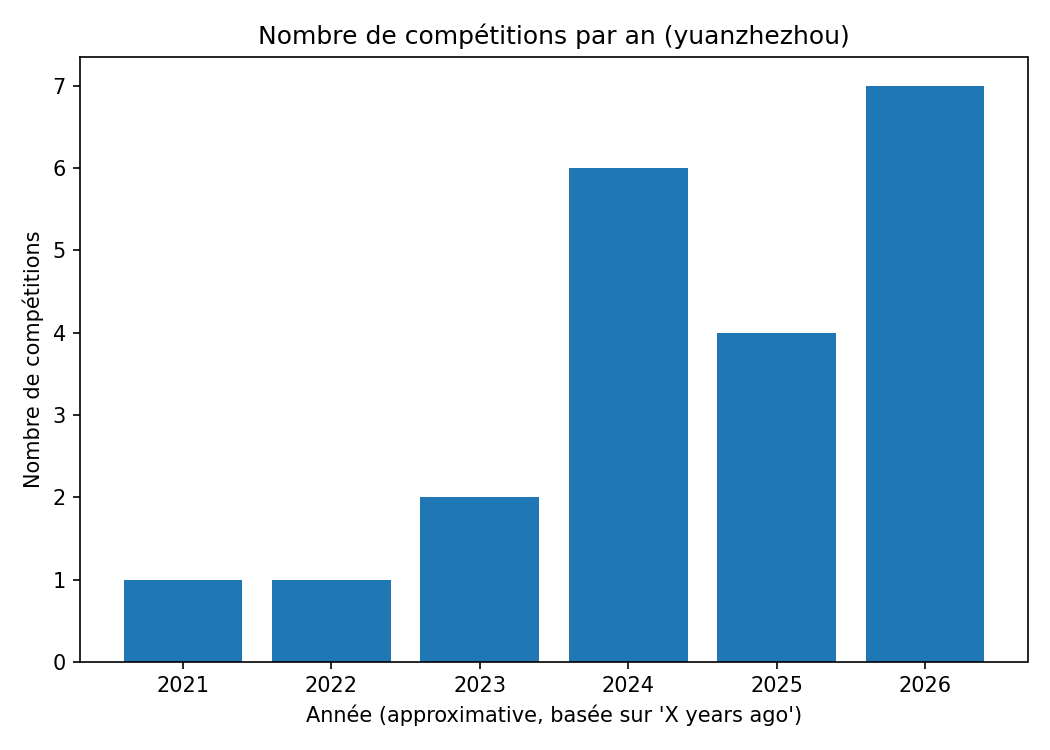
Figure 1 : Nombre de compétitions par an (yuanzhezhou) — les 25 compétitions scrapées
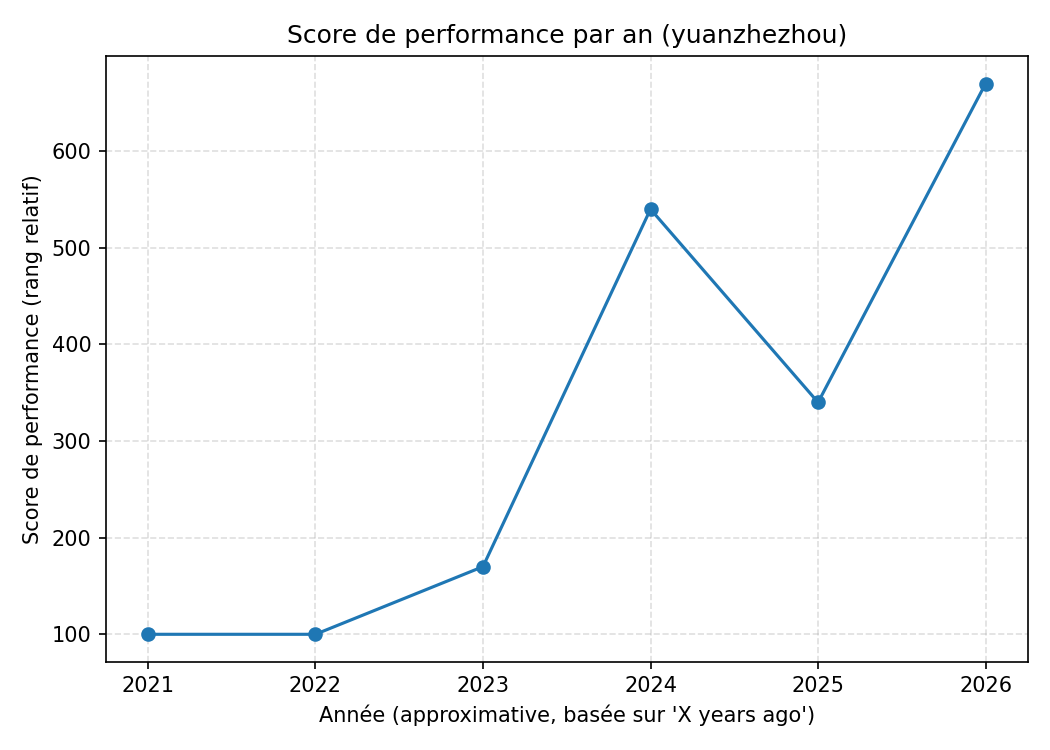
Figure 2 : Score de performance cumulé par an (yuanzhezhou)
Analyse :
Limite : les 25 compétitions scrapées ne représentent pas l’intégralité des 87 compétitions terminées de yuanzhezhou. Le scroll Kaggle priorise les résultats les plus récents et les plus notables (“Best Result” en premier), ce qui peut biaiser la distribution vers les années récentes.
Conclusion : H1 validée — L’intensification de l’activité est massive et coïncide avec la progression au classement.
Question : yuanzhezhou a-t-il basculé du solo vers le travail en équipe ?
Données collectées :
Méthode : Le script sq1_solo_vs_team_timeline.py utilise Playwright pour :
/competitions/<slug>/leaderboardOn classe ensuite chaque compétition comme “solo” (1 membre) ou “équipe” (>1 membre) et on agrège par année.
Données produites : Agrégat annuel solo/team, visualisé directement.
Résultat :
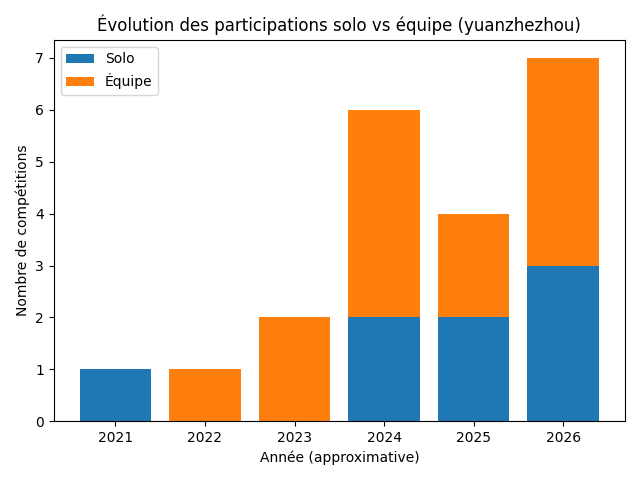
Figure 3 : Évolution des participations solo vs équipe — barplot empilé (yuanzhezhou)
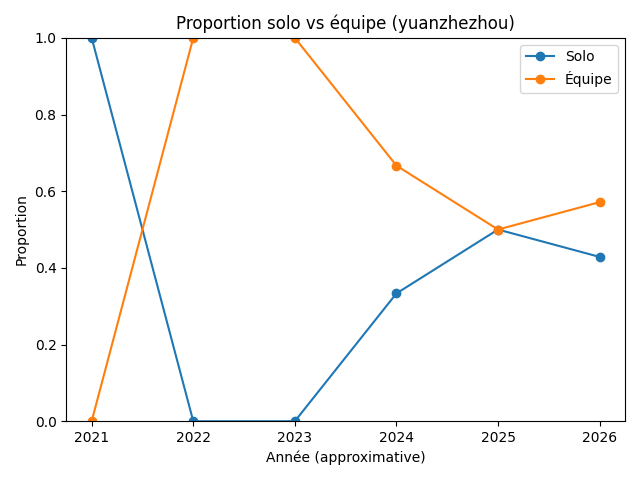
Figure 4 : Proportion solo vs équipe par année (yuanzhezhou)
Analyse :
Conclusion : H2 validée — Le passage au travail d’équipe est un changement structurel majeur dans la stratégie de yuanzhezhou, et il coïncide temporellement avec sa montée au classement.
Question : yuanzhezhou travaille-t-il toujours avec les mêmes coéquipiers ou change-t-il fréquemment ?
Données collectées :
?search=yuanzhezhou, qui affichent les membres de l’équipeMéthode : Le script sq1_teammates_heatmap.py utilise Playwright pour :
/competitions/<slug>/leaderboard?search=yuanzhezhou/account/<username>) visibles sur la page filtréeDonnées produites :
out/user_teammates_raw.csv : 30 lignes — une par (compétition, coéquipier), couvrant 12 compétitions en équipe et 23 coéquipiers uniquesout/user_teammates_matrix.csv : matrice pivot (23 coéquipiers × 5 années)Résultat :
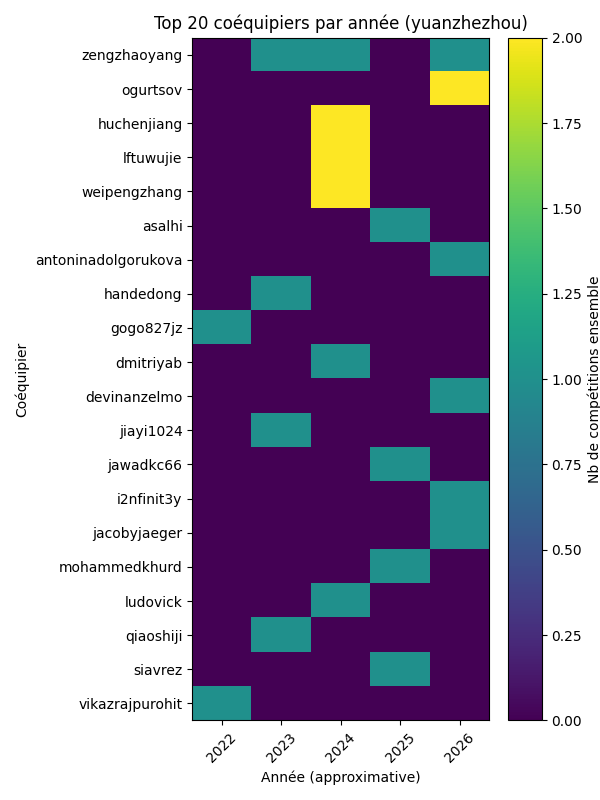
Figure 5 : Heatmap des 20 principaux coéquipiers par année (yuanzhezhou)
Analyse :
Conclusion : H2.1 validée — yuanzhezhou pratique une rotation élevée de coéquipiers (23 coéquipiers uniques pour 12 compétitions en équipe), ce qui maximise son volume de participation.
Question : Les performances de yuanzhezhou sont-elles meilleures quand ses coéquipiers sont mieux classés globalement ?
Données collectées :
Méthode : Le script sq1_team_strength_vs_performance.py :
out/user_teammates_raw.csvout/teammate_global_ranks.json (évite de re-scraper lors de ré-exécutions)Données produites :
out/teammate_global_ranks.json : cache {username: rang global} pour 23 coéquipiersout/user_team_strength.csv : une ligne par compétition avec force d’équipe + performanceRésultat :
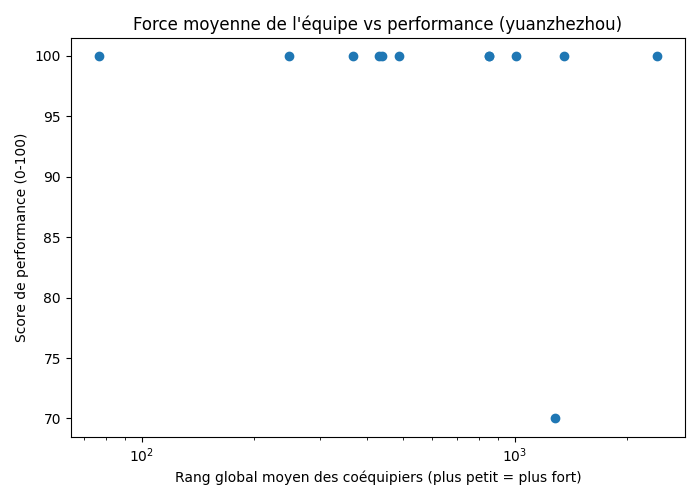
Figure 6 : Scatter plot — Rang moyen des coéquipiers vs score de performance (échelle log pour le rang)
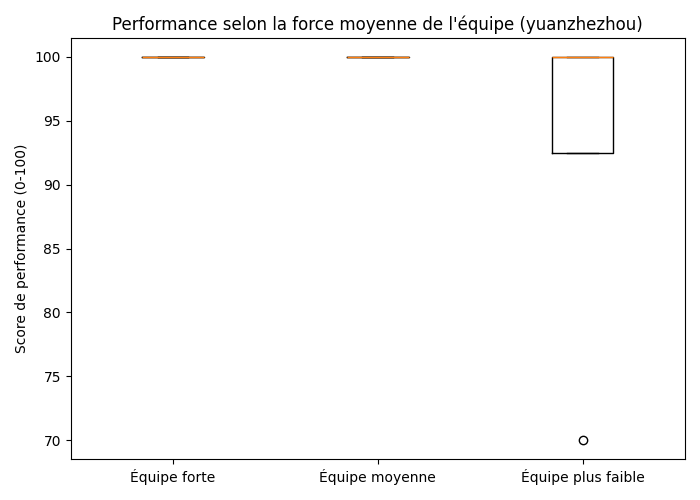
Figure 7 : Boxplot — Performance selon la force de l'équipe (répartition en terciles)
Analyse :
Limite : l’échantillon est petit (12 compétitions en équipe) et le rang global des coéquipiers est mesuré au moment du scraping, pas au moment de la compétition (leur rang a pu changer depuis).
Conclusion : H2.2 validée — La force des coéquipiers est corrélée à la régularité des performances, même si le niveau individuel est déjà très élevé.
Question : Au-delà de yuanzhezhou, les équipes sont-elles structurellement avantagées dans les compétitions Kaggle ?
Pourquoi cette question ? Nous avons montré que yuanzhezhou utilise massivement les équipes. Mais est-ce un avantage réel ou une coïncidence ? Pour le vérifier, nous regardons si les équipes sont sur-représentées dans le haut des leaderboards toutes compétitions confondues, indépendamment de yuanzhezhou.
Données collectées :
TeamMemberUserNames : nombre de noms séparés par des virgules)Méthode : Le script sq1_solo_vs_team_deciles_from_csv.py :
Rank, TeamMemberCount ou TeamMemberUserNames)Ce script fonctionne entièrement offline — il ne fait aucun scraping et utilise uniquement les fichiers ZIP téléchargés à l’étape 3.
Données produites : out/figures_sq1/solo_vs_team_deciles_agg.csv — 10 lignes (une par décile) avec : total participants, count solo, count team, ratios
Résultat :
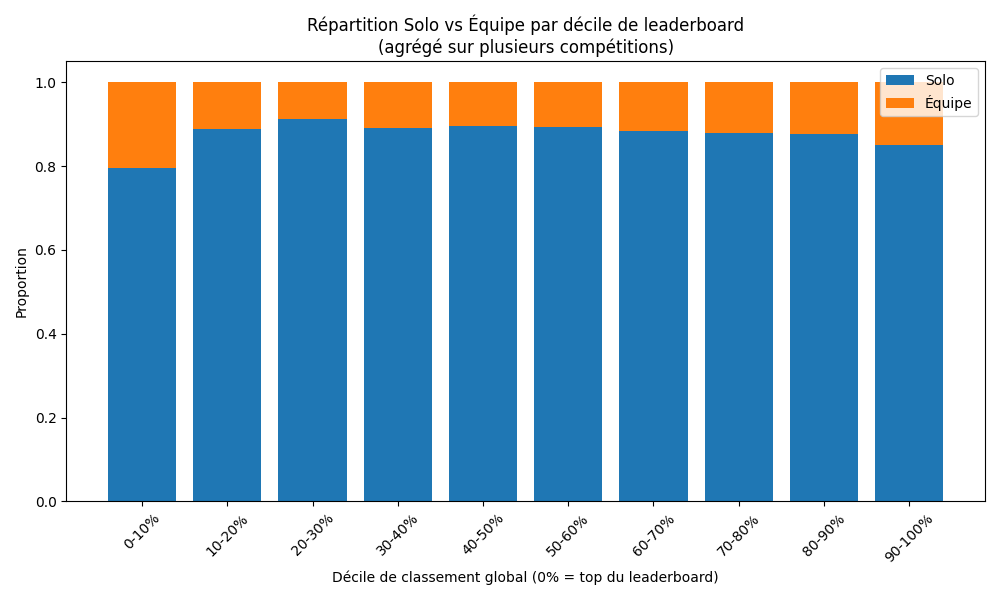
Figure 8 : Répartition solo/équipe par décile de leaderboard (agrégé sur 8 compétitions, 19 897 participants)
Analyse :
Limite : les 8 compétitions analysées ne sont pas un échantillon aléatoire — elles ont été sélectionnées parmi les plus populaires et récentes. Des compétitions moins populaires pourraient montrer un pattern différent.
Conclusion : Généralisation partielle — Les équipes sont statistiquement sur-représentées dans le haut des classements (+5.4pp dans le top 10% vs bottom 10%), confirmant que la stratégie de collaboration de yuanzhezhou est structurellement avantageuse, même si la majorité des top performers sont des solos.
Question : D’autres compétiteurs ayant connu une montée rapide montrent-ils le même pattern d’intensification de la collaboration ?
Pourquoi cette question ? Si seul yuanzhezhou montre ce pattern, il pourrait s’agir d’un cas isolé. Si d’autres “fast risers” montrent la même évolution, le phénomène est structurel et pas anecdotique.
Compétiteurs étudiés (6 au total) :
Pourquoi ces 6 ? Ce sont les compétiteurs du top 25 dont les données étaient déjà scrapées et cachées dans out/fast_risers/ lors de la première exécution. Chaque utilisateur nécessite ~2 minutes de scraping (profil + leaderboards de chaque compétition), et le scraping de 6 utilisateurs a permis d’obtenir un panel représentatif sans dépasser un temps d’exécution raisonnable.
Données collectées :
Méthode : Le script sq1_compare_fast_risers_collab_heatmap.py automatise le pipeline complet pour chaque utilisateur :
teammate_global_ranks.json)team_ratio pondéré à 40% : proportion de compétitions en équipeunique_teammates normalisé à 25% : diversité des partenairesstrength normalisé à 20% : force des coéquipiers (inverse du rang moyen)nb_competitions normalisé à 15% : volume d’activitéJustification des poids : le team_ratio est le facteur dominant (40%) car c’est le signal le plus direct de collaboration. Les unique_teammates (25%) capturent la diversification. La strength (20%) est pondérée moins car elle dépend des coéquipiers disponibles. Le nb_competitions (15%) est un facteur secondaire de volume.
Données produites :
out/fast_risers/<username>_yearly_features.csv : métriques annuelles par utilisateurout/fast_risers/fast_risers_collab_index_pivot.csv : tableau pivot utilisateur × année, avec le collab_indexRésultat :
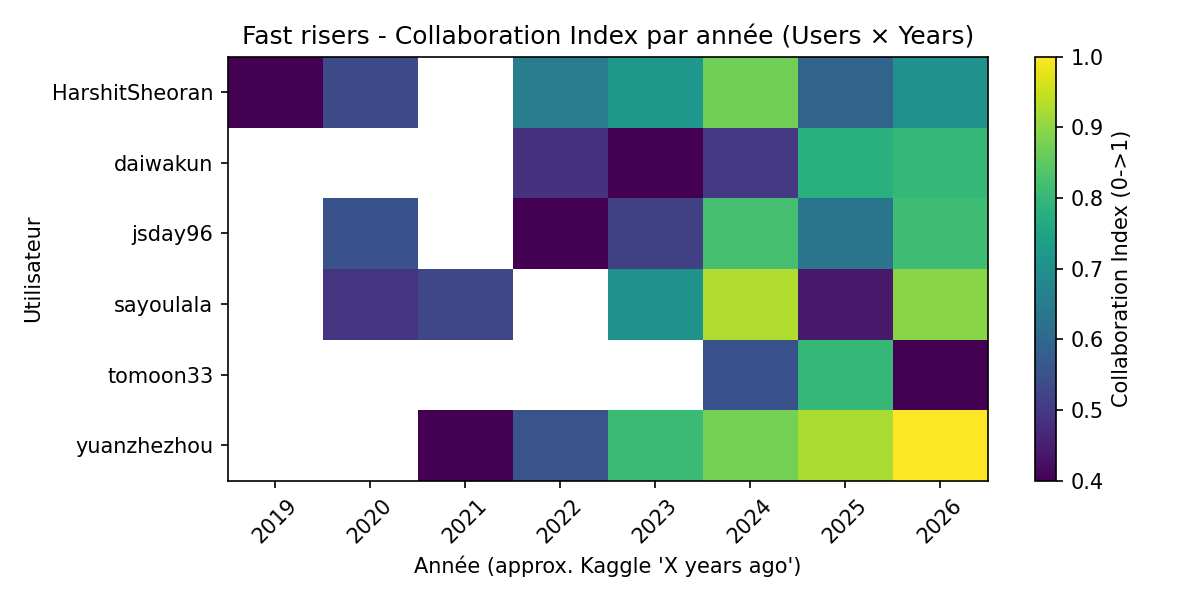
Figure 9 : Collaboration Index par année pour 6 "fast risers" du top 25
Analyse :
Limite : l’échantillon est petit (6 compétiteurs), et tous ont réussi. Nous n’avons pas de groupe de contrôle de compétiteurs ayant échoué malgré une stratégie collaborative.
Conclusion : Pattern généralisable — L’intensification de la collaboration est un facteur commun aux progressions rapides, mais pas le seul chemin vers le top.
Question : Comment les meilleurs compétiteurs mondiaux se comparent-ils en termes de pratiques collaboratives ?
Pourquoi cette question ? Nous voulons situer la stratégie de yuanzhezhou dans le contexte du top mondial entier. Est-il un outlier ou représentatif ? Les autres top performers utilisent-ils les mêmes leviers (équipes, rotation) ou ont-ils des stratégies différentes ?
Compétiteurs étudiés : les 24 premiers du classement global Kaggle au moment de la collecte : yuanzhezhou, tascj0, christofhenkel, cnumber, hydantess, jeroencottaar, wowfattie, jsday96, cpmpml, daiwakun, takoihiraokazu, arc144, conjuring92, aerdem4, tomoon33, mathurinache, harshitsheoran, dc5e964768ef56302a32, philippsinger, chenxin1991, asalhi, sayoulala, ren4yu, brendanartley.
Données collectées :
out/top10/) et la composition de ses équipes (extraite des leaderboards ZIP)Méthode : Le script sq1_top25_collab_from_leaderboard_zips.py :
out/top10/<username>_competitions_raw.csvout/leaderboards/TeamMemberUserNamesteam_ratio, rotation, stability, avg_team_size, unique_matesmin_zips_present=1) — 8 utilisateurs sont exclus car aucune de leurs compétitions n’est couverte par nos 8 ZIPsDonnées produites : out/top10/top25_collab_metrics_from_zips.csv — 24 lignes, une par utilisateur, avec toutes les métriques brutes et normalisées. Après filtrage : 16 utilisateurs retenus.
Résultat :
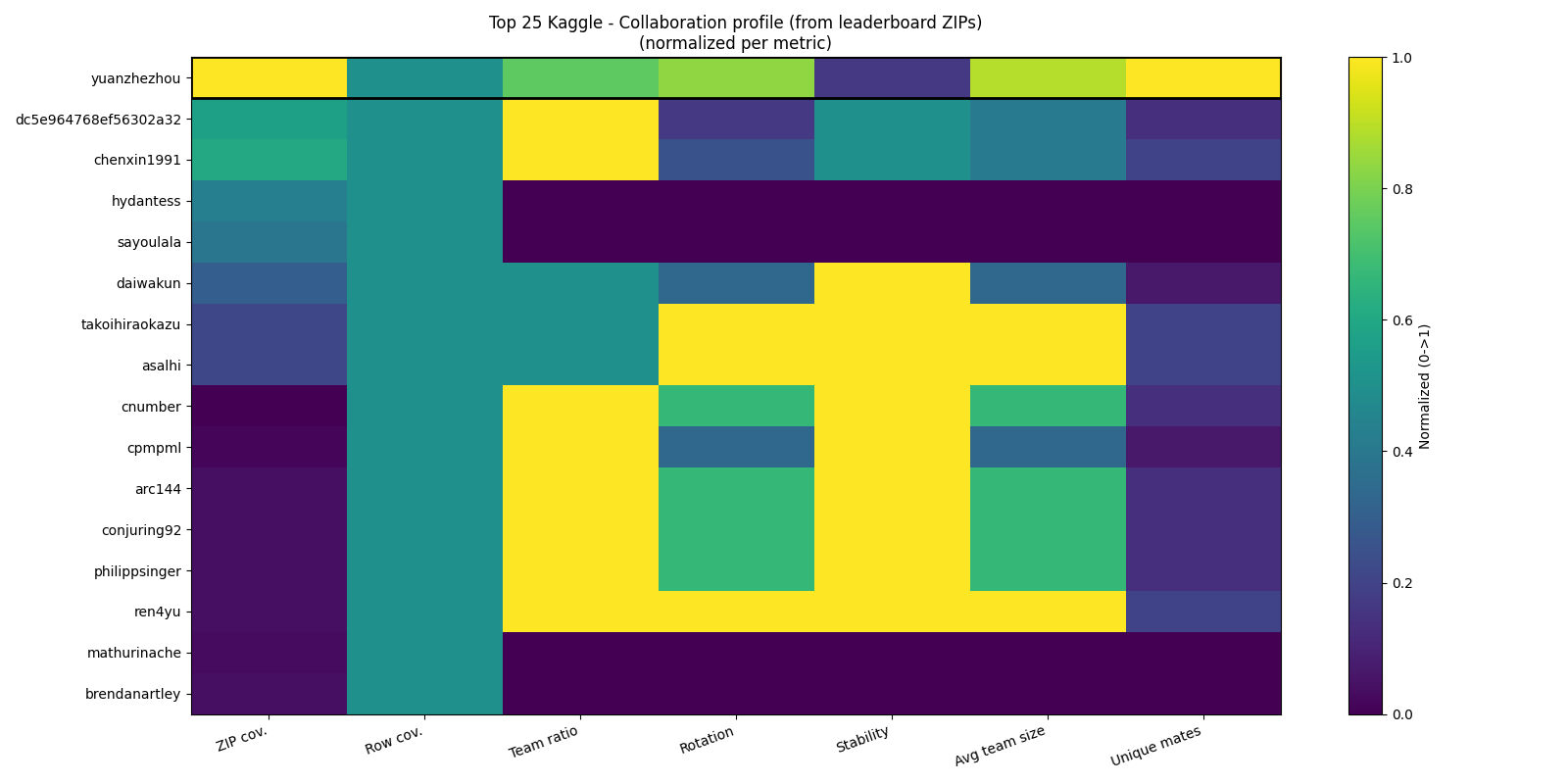
Figure 10 : Profil de collaboration du Top 25 Kaggle — 16 utilisateurs retenus (normalisé par métrique, min-max)
Analyse :
Limite majeure : cette expérience ne couvre que les compétitions pour lesquelles nous avons téléchargé les ZIPs (8 sur les centaines disponibles). Pour yuanzhezhou, cela représente 8 compétitions sur 26 scrapées (31% de couverture). Pour les autres utilisateurs, la couverture est souvent inférieure. Les métriques sont donc basées sur un sous-ensemble des compétitions réelles.
Conclusion : Il n’y a pas une seule stratégie gagnante dans le top 25, mais la stratégie de yuanzhezhou (forte rotation + nombreux coéquipiers) est la plus extrême et la plus distinctive. D’autres voies existent : équipes stables, profils mixtes solo/team.
| Hypothèse | Expérience | Statut | Résultat clé |
|---|---|---|---|
| H1 — Intensification | Exp. 1 | Validée | x7 compétitions/an, x6.7 score |
| H2 — Solo vers équipe | Exp. 2 | Validée | 0% vers 100% équipe (2020-2022) |
| H2.1 — Rotation | Exp. 3 | Validée | 23 coéquipiers uniques pour 12 compétitions en équipe |
| H2.2 — Force équipe | Exp. 4 | Validée | Équipes fortes = top 1% régulier |
| Gén. compétitions | Exp. 5 | Partielle | Équipes sur-représentées dans le top (+5.4pp), 19 897 participants |
| Gén. fast risers | Exp. 6 | Validée | Pattern récurrent chez 6/6 compétiteurs |
| Gén. top 25 | Exp. 7 | Nuancée | yuanzhezhou = profil le plus extrême, mais pas le seul chemin |
competitions list) donne les dates exactes des compétitions, mais ne permet pas de croiser avec l’historique d’un utilisateur (pas d’endpoint “compétitions auxquelles l’utilisateur X a participé”). Il faudrait croiser manuellement la liste complète des compétitions Kaggle (des milliers) avec les slugs extraits par scraping, ce qui est faisable mais dépasse le périmètre de ce projet. En pratique, l’approximation à l’année est suffisante pour nos analyses par année.dc5e964768ef56302a32) pour une étude académique sans affiliation institutionnelle reconnue a peu de chances d’aboutir. De plus, les meilleurs compétiteurs sont très sollicités et répondent rarement aux sollicitations non institutionnelles.Comment le numéro 1 du leaderboard global est-il passé de 0 à héros ?
Notre analyse empirique révèle que la progression de yuanzhezhou repose sur une stratégie d’engagement intensive et collective, mesurable à travers quatre leviers :
Cette stratégie se généralise partiellement :
La collaboration est donc un levier structurel de performance sur Kaggle, mais pas le seul chemin vers le sommet. La stratégie de yuanzhezhou (rotation maximale + coéquipiers forts) est la plus extrême du top 25.
Tous les scripts sont dans assets/scripts/ :
| Fichier | Expérience | Entrée | Sortie |
|---|---|---|---|
reproduce.sh |
Orchestration | — | Exécute les 7 scripts, copie les PNG |
02_login_save_state.py |
Pré-requis | Connexion manuelle | kaggle_state.json |
sq1_scrape_timeline_user.py |
Exp. 1 | Profil Kaggle (scraping) | out/user_competitions_raw.csv, Fig. 1-2 |
sq1_solo_vs_team_timeline.py |
Exp. 2 | CSV exp. 1 + leaderboards (scraping) | Fig. 3-4 |
sq1_teammates_heatmap.py |
Exp. 3 | CSV exp. 1 + leaderboards (scraping) | out/user_teammates_raw.csv, Fig. 5 |
sq1_team_strength_vs_performance.py |
Exp. 4 | CSV exp. 3 + profils (scraping) | out/teammate_global_ranks.json, Fig. 6-7 |
sq1_solo_vs_team_deciles_from_csv.py |
Exp. 5 | ZIPs leaderboards (offline) | Fig. 8 |
sq1_compare_fast_risers_collab_heatmap.py |
Exp. 6 | Profils + leaderboards (scraping) | Fig. 9 |
sq1_top25_collab_from_leaderboard_zips.py |
Exp. 7 | CSVs + ZIPs (offline) | Fig. 10 |
Voir la section 0 en début de document et
assets/scripts/README.mdpour les instructions complètes de reproduction.