Est-ce que les tops du leaderboard se spécialisent ?
Cette partie a été réalisée par : Ascari Yannick - Groupe G.
Sommaire
- Introduction
- Méthodologie
- Mis en œuvre
- Résultats
- Conclusion
- Limites
- Notions acquises
- Références
Introduction
Kaggle est une plateforme, permettant aux data scientists de pouvoir s’affronter dans des compétitions
d’intelligence artificielle (IA). Cette plateforme permet aux data scientists de se mesurer et ainsi, de trouver de nouvelles idées
pour améliorer l’écriture de code, pour avoir des meilleurs modèles tout en restant très performants. Kaggle met à disposition ces
compétitions à tout le monde, en libre-service, et aussi depuis une API pour pouvoir étudier plus en profondeur tout les aspects
de chaque compétition.
On peut alors s’intéresser, si à travers toutes ces compétitions, on peut observer si dans chaque compétition, les meilleurs compétiteurs
se spécialisent dans un domaine spécifique précis, et donc si cette stratégie de spécialisation est payante pour être dans le podium.
La question que l’on se pose est donc : Est-ce que les tops du leaderboard se spécialisent ?
Hypothèse
L’hypothèse principale, est que la focalisation dans un domaine précis de compétition *Kaggle est une stratégie gagnante pour être dans le podium*.
Méthodologie
Afin de répondre à cette question, nous allons suivre la méthodologie suivante, dans l’ordre chronologique.
- Tout d’abord, s’accommoder avec la plateforme Kaggle, essayer de comprendre comment fonctionne les compétitions et comment
sont traitées les différentes données pour pouvoir mieux les analyser. Notamment comment est-ce que les compétitions
classent les compétiteurs et trouver la catégorie de la compétition, par exemple si c’est une compétition NLP, tabulaire,
séries temporelles, etc. Cela permet de pouvoir mieux comprendre le système avant de le traiter.
- Une fois que l’on s’est bien accommodé avec Kaggle, et que l’on a bien compris son système, on essaye de mettre en place
notre propre système de traitement des données. C’est-à-dire que l’on fait un choix, de comment est-ce qu’on va pouvoir visualiser
les données, et quelles sont les métriques que l’on va utiliser pour pouvoir répondre à la question que l’on se pose. Dans notre cas,
pour chaque compétition, on va extraire les compétiteurs et le domaine associé, pour pouvoir calculer pour chaque compétiteur, sa distribution
de participations par domaine et déterminer son taux de spécialisation, ce sera notre principale métrique. Cette étape consiste surtout à
bien comprendre quels métriques nous allons décider d’utiliser pour répondre à la question, ce qui est très important pour bien répondre à cette dernière. (C’est
comme un plan, on explique comment est-ce que l’il faut procéder pour construire notre réponse).
- Après avoir bien construit notre plan, et identifier les métriques, il faut donc pouvoir mettre en place le système de traitement des données, permettant
de calculer les métriques que l’on a décidées d’utiliser. Dans notre cas, on va utiliser l’API Kaggle, et utiliser Python pour mettre en place un système
automatisé qui pourra calculer la métrique. On utilisera Python, car c’est le langage le plus simple et adapté pour utiliser pleinement l’API Kaggle, et
aussi le plus simple pour faire ce genre de scripts et systèmes automatisés. À noter que cela demande aussi d’avoir une très bonne connaissance de la documentation de
l’API Kaggle.
- Une fois que notre système pourra calculer nos métriques, on pourra répondre à notre problématique, en créant des visualisations. En s’appuyant depuis
nos métriques, on pourra créer des schémas et des graphiques pour bien observer nos résultats et pouvoir tirer une conclusion, si oui ou non est-ce que le fait
de spécialiser dans un domaine précis est une stratégie gagnante pour être dans le podium. Ces graphiques et schémas seront réalisés aussi grâce au langage de programmation
Python, qui est aussi très adapté pour faire des visualisations de données. On utilisera des bibliothèques comme Matplotlib, qui nous permet facilement de faire des graphiques.
Les différents types de graphiques que l’on mettra en place seront surtout des histogrammes, et une heatmap pour bien visualiser la spécialisation des compétiteurs.
- Finalement, une fois que l’on aura obtenu nos résultats depuis ces différentes visualisations, on pourra en tirer une conclusion, et donc répondre à la problématique de base.
Cela demande de bien analyser les résultats, et de savoir interpréter les graphiques que l’on a mis en place, pour pouvoir en tirer une conclusion pertinente. On pourra grâce à
ces visualisations donner une réponse précise avec des chiffres et des pourcentages à l’appui, pour avoir une réponse plus nuancée et pas forcément binaire. Cela permet d’apporter
une réponse beaucoup plus scientifique à notre problématique et participer au travail de rétro-ingénierie.
Une fois que nous avons bien défini notre méthodologie, on peut passer à la prochaine étape, qui consiste à la mise en œuvre de celle-ci.
Mise en œuvre
Afin de mettre la méthodologie en œuvre, on a suivi les points suivants :
- Accommodement avec Kaggle : J’ai tout d’abord commencé par bien m’accommoder au système de Kaggle, en parcourant notamment les différentes compétitions et
en explorant les leaderboards. J’ai essayé de voir comment est-ce que les compétitions sont classées, et comment est-ce que les compétiteurs sont notés. Cela m’a permis
d’identifier les différentes catégories de compétitions, et aussi de comprendre comment est-ce que les compétiteurs sont classés dans chaque compétition. Ce qui est très
important pour identifier mes métriques, et comment est-ce que je pouvais bien mettre en place mon système de traitement des compétitions Kaggle. Cela m’a amené à l’étape
d’après sur le choix des métriques.
- Choix des métriques : Une fois que j’ai bien compris le système de Kaggle, j’ai pu choisir les métriques que j’allais utiliser pour répondre à ma problématique.
J’ai décidé de me concentrer sur le taux de spécialisation des compétiteurs, c’est-à-dire la proportion de compétitions dans un domaine précis par rapport au total des compétitions
auxquelles ils ont participé. J’ai aussi décidé de regarder la distribution des participations par domaine pour chaque compétiteur, pour voir s’il y a une tendance à se spécialiser
dans un domaine précis. Ces métriques me semblaient les plus pertinentes pour répondre à ma question.
- Mise en place du système de traitement : Dans cette étape, j’ai utilisé l’API Kaggle pour extraire les données des compétitions et des compétiteurs. J’ai écrit un script en Python qui
pouvait automatiser le processus de collecte des données, et calculer les métriques que j’avais choisies. On peut retrouver le code de script dans le fichier Python src/kaggle/analyze_specialization.py,
celui-ci contient donc le code complet pour calculer notre métrique, le taux de spécialisation des compétiteurs. Dans ce code il y a trois parties, qui sont des fonctions :
get_filtered_competitions() (l.18) : Permet de récupérer les compétitions filtrées selon les domaines de spécialisation. (ex : NLP, tabulaire, etc.)get_leaderboard_for_competitions() (l.66) : Récupère les leaderboards pour chaque compétition filtrée.build_specialization_matrix() (l.111) : Calcule la matrice de spécialisation des compétiteurs en fonction des domaines, depuis notre métrique principale.
La fonction main() (l.141) s’occupe d’appeller ses fonctions, et de sauvergarder la métrique dans un fichier au format csv pour pouvoir l’utiliser dans l’étape suivante. On peut retrouver ces fichiers
dans le dossier /data. Il y a donc deux fichiers csv générés :
/data/filtered_competitions.csv : Contient la liste des compétitions filtrées selon les domaines de spécialisation./data/specialization_matrix.csv : Contient la matrice de spécialisation des compétiteurs, calculée depuis le script.
À savoir que j’ai fait le choix de bien séparer le code python avec deux scripts, un pour le calcul des métriques, et un autre pour les visualisations, afin de garder un code propre, organisé et structuré.
- Création des visualisations : Une fois que j’ai pu calculer mes métriques, on peut maintenant se focaliser sur la création des graphiques, et des schémas. J’ai donc écrit le code dans le
fichier src/kaggle/visualize_specialization.py, qui contient l’implémentation des visualisations à partir du fichier précèdent en s’appuyant des métriques
calculées danns ce dernier. Comme dans l’étape précédente, on peut découper le code de cette implémentation en plusieurs parties principales :
load_data() (l.19) : Permet de charger la métrique, calculé par le script précédent depuis le fichier csv, dans le script en mémoire.plot_top_competitors_heatmap(df, top_n=50) (l.27) : Crée une heatmap pour visualiser la spécialisation des meilleurs compétiteurs. Ce qui est particulièrement utile pour observer les tendances de spécialisation.plot_specialization_distribution(df) (l.61) : Crée un histogramme pour visualiser la distribution des taux de spécialisation parmi tous les compétiteurs. Cela permet de voir si la majorité des compétiteurs se spécialisent ou non,
avec des chiffres précis, pour avoir un résultat moins binaire et scientifique.plot_average_specialization_bars(df) (l.86) : Crée un graphique à barres pour visualiser le taux de spécialisation moyen par domaine. Cela permet de voir quels domaines sont les plus prisés parmi les meilleurs compétiteurs.plot_top_vs_rest(df, threshold=10) (l.118) : Crée un graphique comparant le taux de spécialisation des meilleurs compétiteurs par rapport au reste. Cela permet de voir si les meilleurs compétiteurs ont tendance à se spécialiser plus que les autres.generate_summary_stats() (l.163) : Génère des statistiques résumées sur les taux de spécialisation, pour avoir une vue d’ensemble des tendances observées, cette visualisation n’est pas une image, seulement des logs dans la console.
- Analyse des résultats et conclusion : Après avoir généré les visualisations, j’ai analysé les résultats obtenus. J’ai observé les graphiques et les schémas pour voir s’il y avait des tendances claires, et si oui ou non les meilleurs compétiteurs avaient
tendance à se spécialiser dans un domaine précis. Cela me permet donc de passer à la prochaine partie, c’est-à-dire les résultats obtenus.
Résultats
Après avoir mis en place le système de traitement des données et généré les visualisations, voici les résultats obtenus. Pour chaque visualisation, on peut observer les tendances suivantes :
- Heatmap de spécialisation des meilleurs compétiteurs : La heatmap montre clairement que les meilleurs compétiteurs ont tendance à se spécialiser dans certains domaines, parmis les 3 domaines que j’ai sélectionnés (NLP, Tabulaire, Time Series Analysis), on peut
voir qu’il y a un forte concentration de compétiteur qui se spécialisent dans le domaine du tabulaire. Ce qui suggère que la spécialisation est une stratégie gagnante pour être dans le podium.
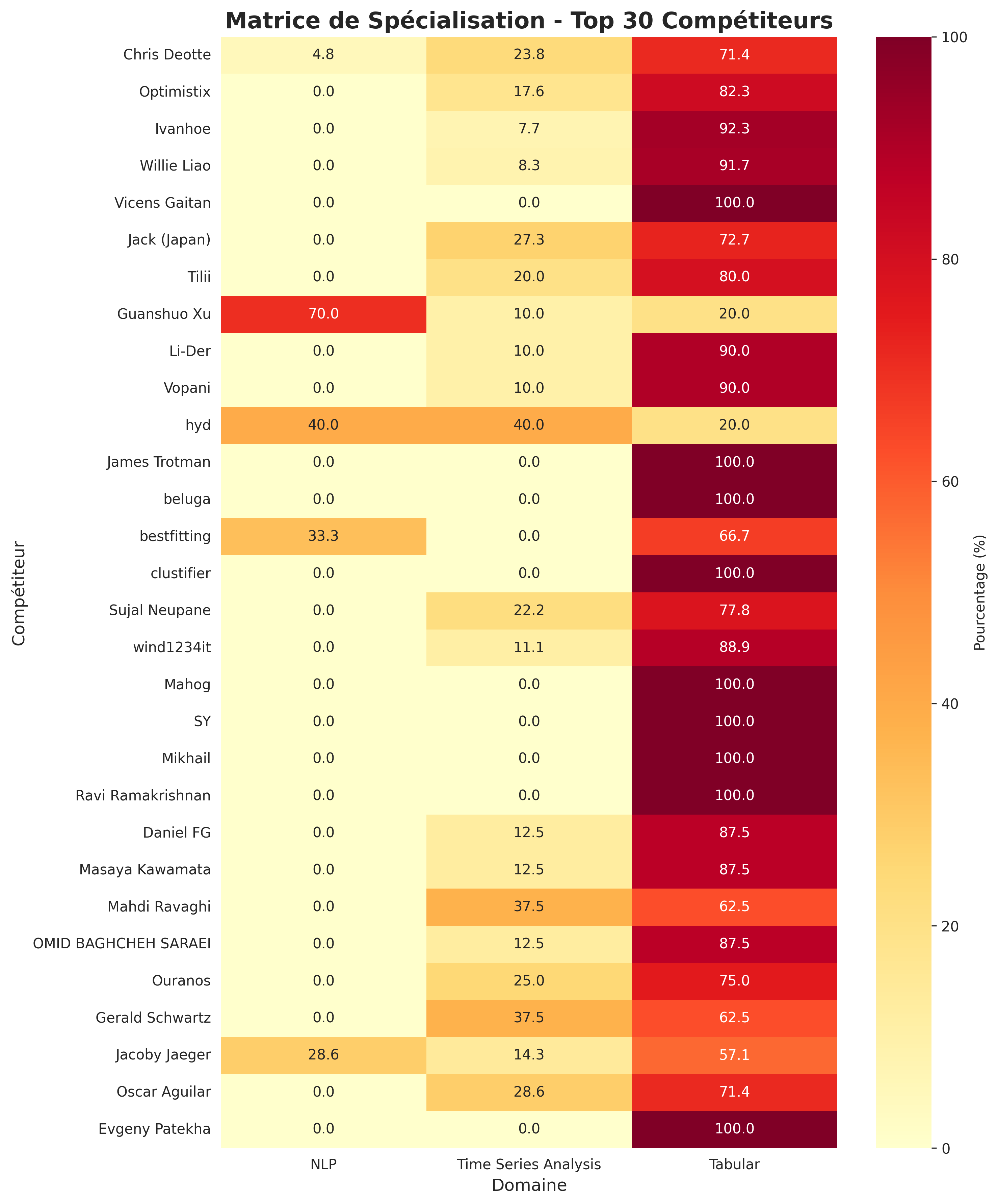
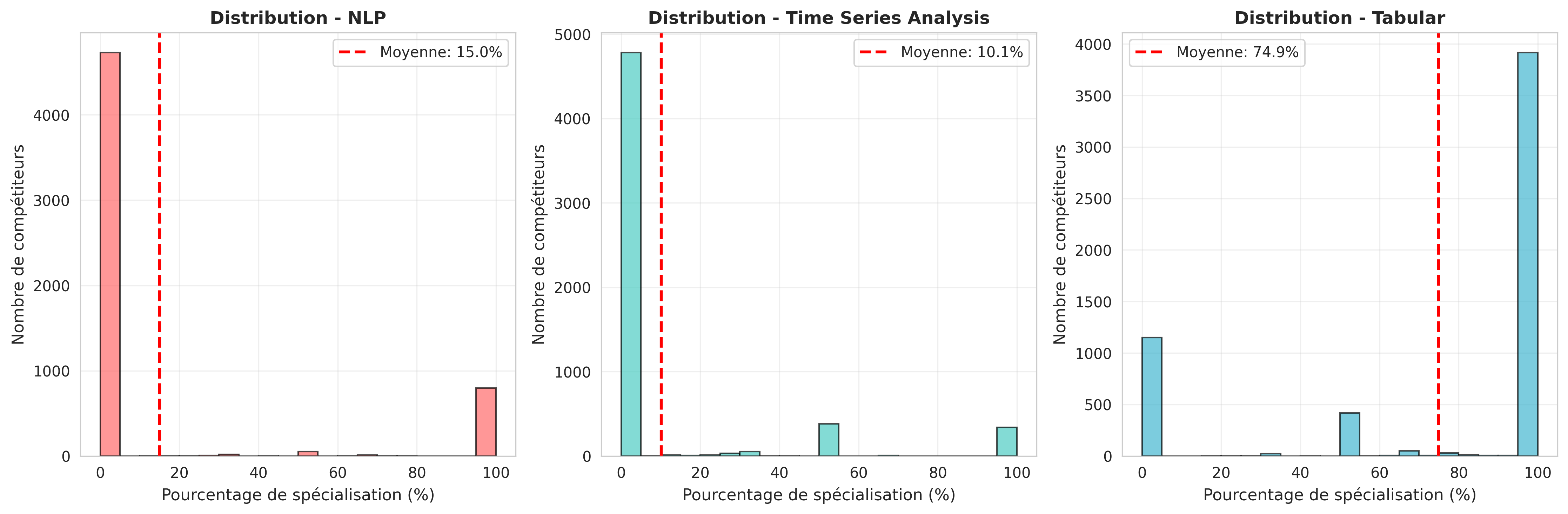
- Distribution des taux de spécialisation : Pour chaque histogramme par catégorie, parmi les 3 catégories, on peut observer que les compétiteurs ont tendance à se spécialiser plutôt dans le domaine du tabulaire, avec une majorité de compétiteurs ayant un taux de spécialisation élevé dans ce domaine en moyenne avec $74.9\%$.
Ce qui confirme encore une fois que les compétiteurs se spécialisent et se focalisent beaucoup dans ce domaine. Pour ce qui est des autres domaines, on à un taux de $15.0 \%$ pour le domaine du NLP, et $10.1\%$ pour le domaine des séries temporelles. Ce qui est nettement moins élevé que le domaine du tabulaire.
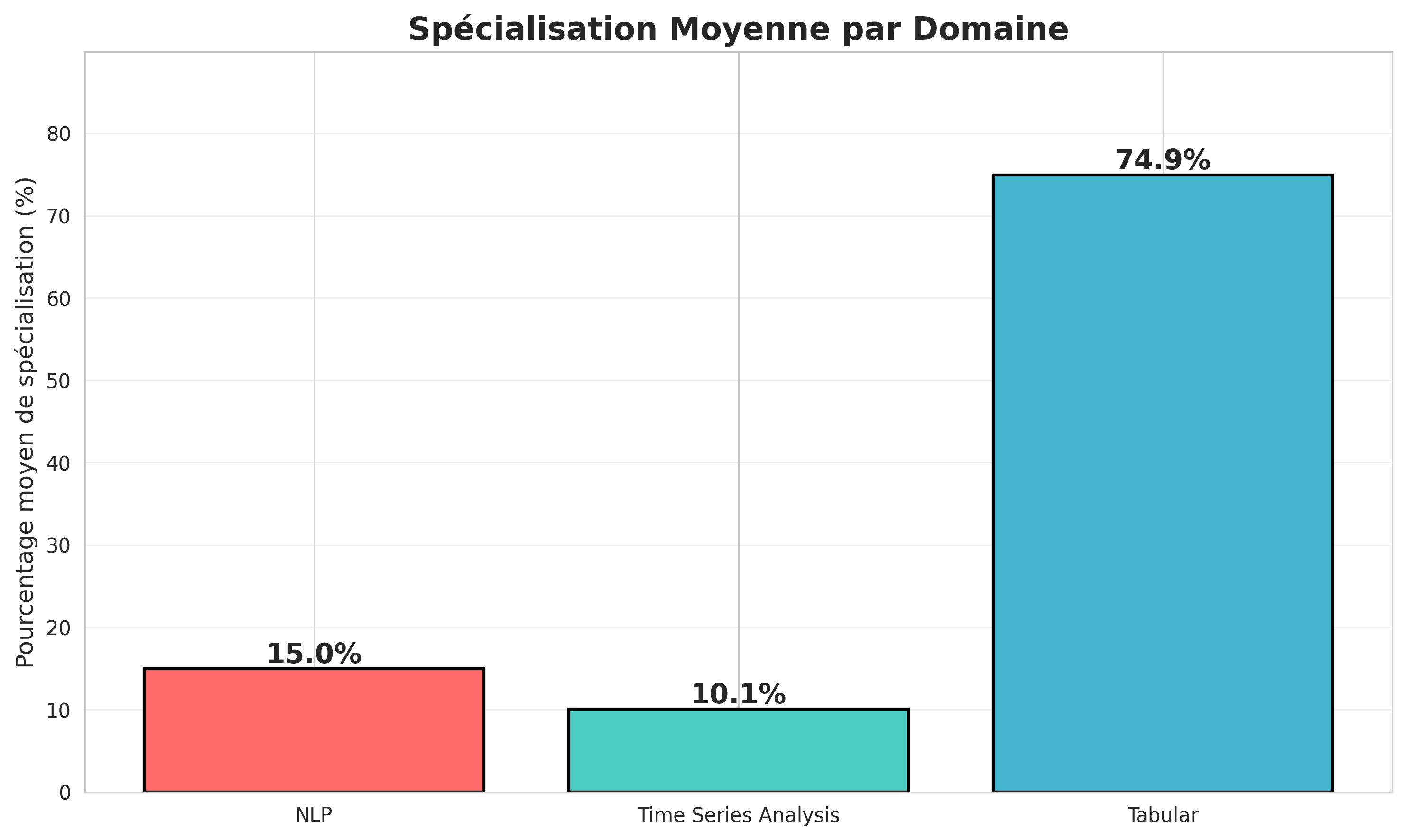
- Taux de spécialisation moyen par domaine : Le graphique à barres montre que le taux de spécialisation moyen est le plus élevé dans le domaine du tabulaire, avec une moyenne de $74.9\%$. Ce qui est nettement plus élevé que les autres domaines, avec $15.0\%$ pour le NLP et $10.1\%$ pour les séries temporelles.
Cela suggère que les compétiteurs qui se spécialisent dans le domaine du tabulaire ont un avantage significatif pour être dans le podium.
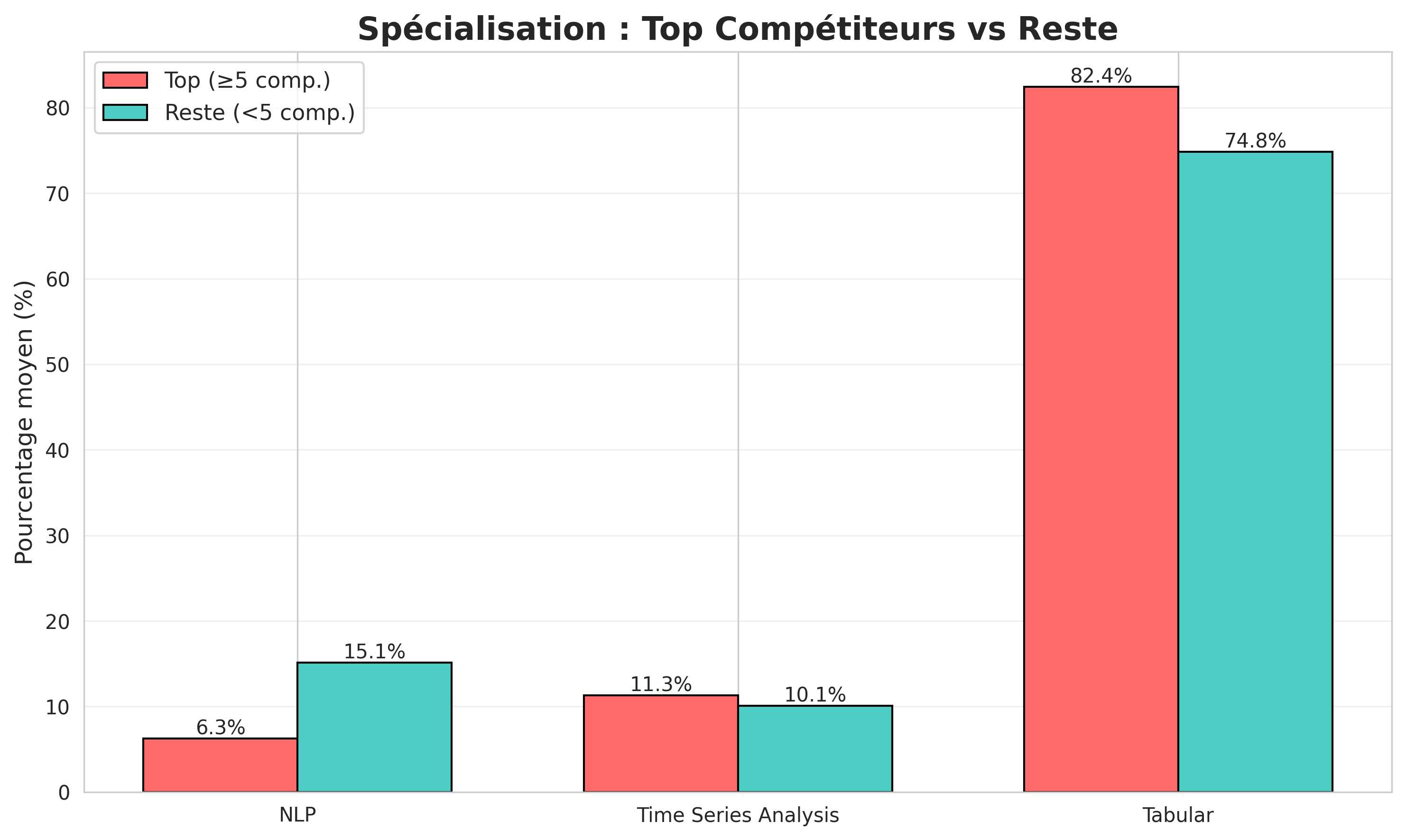
- Comparaison entre les meilleurs compétiteurs et le reste : Le graphique comparant les meilleurs compétiteurs au reste montre que les meilleurs compétiteurs ont un taux de spécialisation significativement plus élevé que les autres. En moyenne, les meilleurs compétiteurs ont un taux de spécialisation très élevé de $82.4\%$ contre $74.8\%$
dans le domaine du tabulaire. Ce qui confirme encore une fois que la spécialisation est une stratégie gagnante pour être dans le podium.
Reproductibilité
À savoir que ce code à été écrit de manière à être reproductible, c’est-à-dire que n’importe qui peut exécuter ce code pour obtenir les mêmes résultats. En outre, le code est aussi écrit
de manière générique, ce qui permet de facilement modifier les paramètres, comme par exemple les domaines de spécialisation, ou le nombre de meilleurs compétiteurs à analyser.
Une fois avoir analysé ces résultats, on peut en tirer une conclusion pertinente.
Conclusion
Après avoir analysé les résultats obtenus, on peut conclure que les meilleurs compétiteurs sur Kaggle ont tendance à se spécialiser dans certains domaines précis, notamment dans le domaine du tabulaire. La spécialisation semble être une stratégie gagnante pour être dans le podium, avec des taux de spécialisation significativement plus élevés parmi les meilleurs compétiteurs.
Cependant, il est important de noter que cette spécialisation n’est pas exclusive, et que certains compétiteurs peuvent également participer à des compétitions dans d’autres domaines. On le voit bien avec les résultats obtenus, qui montrent une tendance claire à la spécialisation avec $\simeq 75\%$.
Donc au final, on peut répondre à la question initiale : Est-ce que les tops du leaderboard se spécialisent ?
Par un relatif oui, les tops du leaderboard ont bien tendance à se spécialiser, notamment dans le domaine du tabulaire, mais cette spécialisation n’est pas absolue, et il y a toujours une part de compétiteurs qui participent à des compétitions dans d’autres domaines. La spécialisation est donc une stratégie gagnante, mais elle n’est pas la seule voie vers le succès sur Kaggle.
Limites
Cependant, il est important de noter certaines limites dans cette analyse :
- Biais du survivant : L’analyse se base uniquement sur les compétiteurs actuellement au leaderboard, ignorant ceux qui ont abandonné Kaggle, ce qui peut créer un biais du survivant, et donc créer du bruit dans les résultats.
- Temporalité du leaderboard : Le leaderboard évolue constamment, et les résultats peuvent varier en fonction du moment où l’analyse est effectuée. Une analyse à un autre moment pourrait donner des résultats différents. Et ce qui rendrait cette analyse un peu obsolète, cependant le leaderboard n’évolue pas aussi vite que ça, donc l’analyse reste pertinente pour un certain temps.
Notions acquises
Grace à ce travail de rétro-ingénierie et d’analyse du système Kaggle, j’ai pu acquérir plusieurs notions importantes :
- Accommodation avec le système existant (Kaggle) : J’ai appris lors de ce travail, à bien comprendre un système existant, en l’occurrence Kaggle, et à m’accommoder avec ses particularités pour pouvoir mieux l’analyser.
Et surtout comprendre comment est-ce que fonctionnaient les compétitions, et comment est-ce que les compétiteurs étaient classés. J’ai du aussi m’accomoder à l’API Kaggle pour pouvoir extraire les données nécessaires, et pouvoir
lire la documentation associée, afin de pouvoir atteindre mon objectif.
- Choisir les bonnes métriques : J’ai appris l’importance de choisir les bonnes métriques pour répondre à une problématique spécifique, et comment ces métriques peuvent influencer les résultats obtenus.
- Création des visualisations : J’ai amélioré mes compétences en création de visualisations de données, en utilisant des bibliothèques comme Matplotlib pour créer des graphiques clairs et informatifs.
Tout ça à l’aide du travail de la création des métriques (étape précédente).
- Analyse des résultats : J’ai appris à analyser les résultats obtenus à partir des visualisations, et à tirer des conclusions pertinentes basées sur ces résultats.
Références
Voici les quelques références utilisées pour ce travail :
- Competing AI: How does competitoon feedback affect machine learning ? (Stanford HAI).
Article - Étude qui démontre que lorsque des algos d’IA entrent en compétition, ils se spécialisent pour des sous-populations d’utilisateurs.
- Learnings from Kaggle’s Forecasting Competitions (arXiv, 2020).
Article - Analyse les stratégies gagnantes dans les compétitions Kaggle, l’essor de XGBoost et des ensembles de modèles.
- The Ladder: A Reliable Leaderboard for Machine Learning Competitions (MLR Press).
Article - Traite la méthodologie d’analyse des leaderboards et des analyses post-compétitions, confirmant la méthodologie utilisée dans ce travail.
- Data competition design and analysis (arXiv, 2019).
Article - Discute des stratégies de conception et d’analyses des compétitions de data science.
février 2026
Authors
We are four students in M2 or in last year of Polytech’ Nice-Sophia specialized in Software Architecture :
- Malik MOUSSA <merwan-malik.moussa-boudjemaa@etu.unice.fr>
- Baptiste ROYER <baptiste.royer@etu.unice.fr>
- Sacha CHANTOISEAU <sacha.chantoiseau@etu.unice.fr>
- Yannick ASCARI <yannick.ascari@etu.unice.fr>
I. Research context /Project
Préciser ici votre contexte et Pourquoi il est intéressant. **
II. Observations/General question
-
Commencez par formuler une question sur quelque chose que vous observez ou constatez ou encore une idée émergente.
-
Préciser pourquoi cette question est intéressante de votre point de vue.
Attention pour répondre à cette question, vous devrez être capable d’émettre des hypothèses vérifiables, de quantifier vos réponses, …
:bulb: Cette première étape nécessite beaucoup de réflexion pour définir la bonne question qui permet de diriger la suite de vos travaux.
Préciser vos zones de recherches en fonction de votre projet, les informations dont vous disposez, …
Voici quelques pistes :
- les articles ou documents utiles à votre projet
- les outils que vous souhaitez utiliser
-
les jeux de données/codes que vous allez utiliser, pourquoi ceux-ci, …
:bulb: Cette étape est fortement liée à la suivante. Vous ne pouvez émettre d’hypothèses à vérifier que si vous avez les informations. inversement, vous cherchez à recueillir des informations en fonction de vos hypothèses.
IV. Hypothesis & Experiences
- Il s’agit ici d’énoncer sous forme d’hypothèses ce que vous allez chercher à démontrer. Vous devez définir vos hypothèses de façon à pouvoir les mesurer/vérifier facilement. Bien sûr, votre hypothèse devrait être construite de manière à vous aider à répondre à votre question initiale. Explicitez ces différents points.
-
Vous explicitez les expérimentations que vous allez mener pour vérifier si vos hypothèses sont vraies ou fausses. Il y a forcément des choix, des limites, explicitez-les.
:bulb: Structurez cette partie à votre convenance :
Par exemples :
Pour Hypothèse 1 =>
Nous ferons les Expériences suivantes pour la démontrer
Pour Hypothèse 2 => Expériences
ou Vous présentez l'ensemble des hypothèses puis vous expliquer comment les expériences prévues permettront de démontrer vos hypothèses.
V. Result Analysis and Conclusion
- Présentation des résultats
- Interprétation/Analyse des résultats en fonction de vos hypothèses
-
Construction d’une conclusion
:bulb: Vos résultats et donc votre analyse sont nécessairement limités. Préciser bien ces limites : par exemple, jeux de données insuffisants, analyse réduite à quelques critères, dépendance aux projets analysés, …
Précisez votre utilisation des outils ou les développements (e.g. scripts) réalisés pour atteindre vos objectifs. Ce chapitre doit viser à (1) pouvoir reproduire vos expérimentations, (2) partager/expliquer à d’autres l’usage des outils.

VI. References
[Debret 2020] Debret, J. (2020) La démarche scientifique : tout ce que vous devez savoir ! Available at: https://www.scribbr.fr/article-scientifique/demarche-scientifique/ (Accessed: 18 November 2022).