janvier 2025
Nous sommes trois étudiants en dernière année de Sustainable Software Engineering, en Sciences Informatiques à Polytech Nice Sophia :
Les Large Language Models (LLM) comme GPT-4 sont des modèles d’IA de grande taille, capables de réaliser des tâches variées avec une haute précision, mais leur développement et leur utilisation nécessitent des infrastructures coûteuses en énergie et en ressources financières. En parallèle, les Small Language Models (SLM), bien que plus limités en capacités, peuvent fonctionner sur des appareils locaux avec des moins de ressources. Ils sont généralement spécialisés dans un domaine particulier (génération de code, dialogues, etc.), même si certains demeurent encore généralistes.
Dans un contexte où les préoccupations environnementales et les coûts d’exploitation deviennent de plus en plus important, il devient essentiel de comparer ces deux catégories de modèles sur leur efficacité énergétique et financière. Ce sont des sujets d’avenir et de plus en plus mis en avant par les grosses entreprises.
Réduction de l’empreinte carbone : L’entraînement et l’utilisation des LLM dans le cloud consomment une quantité importante d’énergie, générant une empreinte carbone élevée. Comparer cela avec des SLM peut révéler des opportunités pour des pratiques plus durables. Malgré les avancées très rapides dans le domaine, cela peut permettre de guider certains choix.
Optimisation des coûts : Les LLM nécessitent souvent des clusters de serveurs spécialisés, tandis que les SLM peuvent s’exécuter sur du matériel standard, souvent moins cher. Les coûts du hardware mais aussi de l’énergie nécessaire aux entraînements et à l’inférence peuvent être fortement diminués avec les SLM.
Accessibilité et démocratisation de l’IA : Les SLM, grâce à leur simplicité et leur faible coût d’exploitation, rendent l’IA accessible à un plus grand nombre de développeurs et d’entreprises, en particulier ceux qui n’ont pas les moyens d’investir dans le cloud ou des infrastructures coûteuses. De plus, le nombre de requêtes a explosé ces dernières années, en augmentant de plus de 100% par rapport à l’année précédente.
Contexte réglementaire et RSE : Dans un monde où les entreprises sont de plus en plus incitées à réduire leur empreinte écologique et à s’aligner sur des objectifs de développement durable, cette étude peut les aider à orienter leurs décisions en fonction de critères environnementaux et sociaux.
En somme, cette étude répond à des enjeux technologiques, économiques, et environnementaux majeurs, tout en ouvrant la voie à des modèles plus responsables et accessibles.
Dans quelle mesure les Small Language Models (SLM) sont-ils plus efficaces énergétiquement et financièrement que les Large Language Models (LLM), en prenant en compte les phases d’entraînement et d’utilisation ?
Cette approche permet de poser des hypothèses mesurables et de fournir des résultats chiffrés sur l’efficacité comparative des LLM et SLM.
Les hypothèses que l’on pourrait faire seraient :
Une première limite se trouve dans la littérature, notamment pour les SLM qui est un sujet de recherche assez récent et ne présentant pas une documentation très large et peu chiffrée.
Les méthodes de calcul, de consommation CO², de coûts financiers ne sont pas très précises ni détaillées en général, ce qui peut mener à des incertitudes.
De la même façon, lorsque l’on compare deux modèles ensemble, il vaut mieux récupérer des résultats de la même étude, du même site, et surtout comparer deux modèles de la même famille pour que l’on soit plus ou moins sûr que l’entreprise les a développé et entrainé dans des conditions similaires. Cela réduit notre sélection de données provenant de SLM.
Il est également compliqué de comparer les performances de différents modèles entre le cloud et une infrastructure locale en raison des variations de matériel. Les résultats obtenus peuvent fournir une indication utile, mais ils ne peuvent pas être pris au pied de la lettre.
Aussi, nous pouvons noter que nous abordons un sujet en perpetuelle évolution. Entre le début de nos recherches et aujourd’hui, des avancées ont été annoncées par les géants du domaine. En autre, Nvidia a annoncé l’arrivée d’une nouvelle “machine” accessible aux particuliers permettant de lancer des modèles allant jusqu’à 200 milliards de paramètres. Ainsi, nous pouvons imaginer que le seuil entre les SLM et les LLM pourraient varier avec l’avancée des unités de calculs.
Tout d’abord, afin de bien centrer le sujet, commençons par définir la notion relativement floue de SLM par rapport aux LLM que l’on connait mieux.
Voici un tableau récapitulatif :
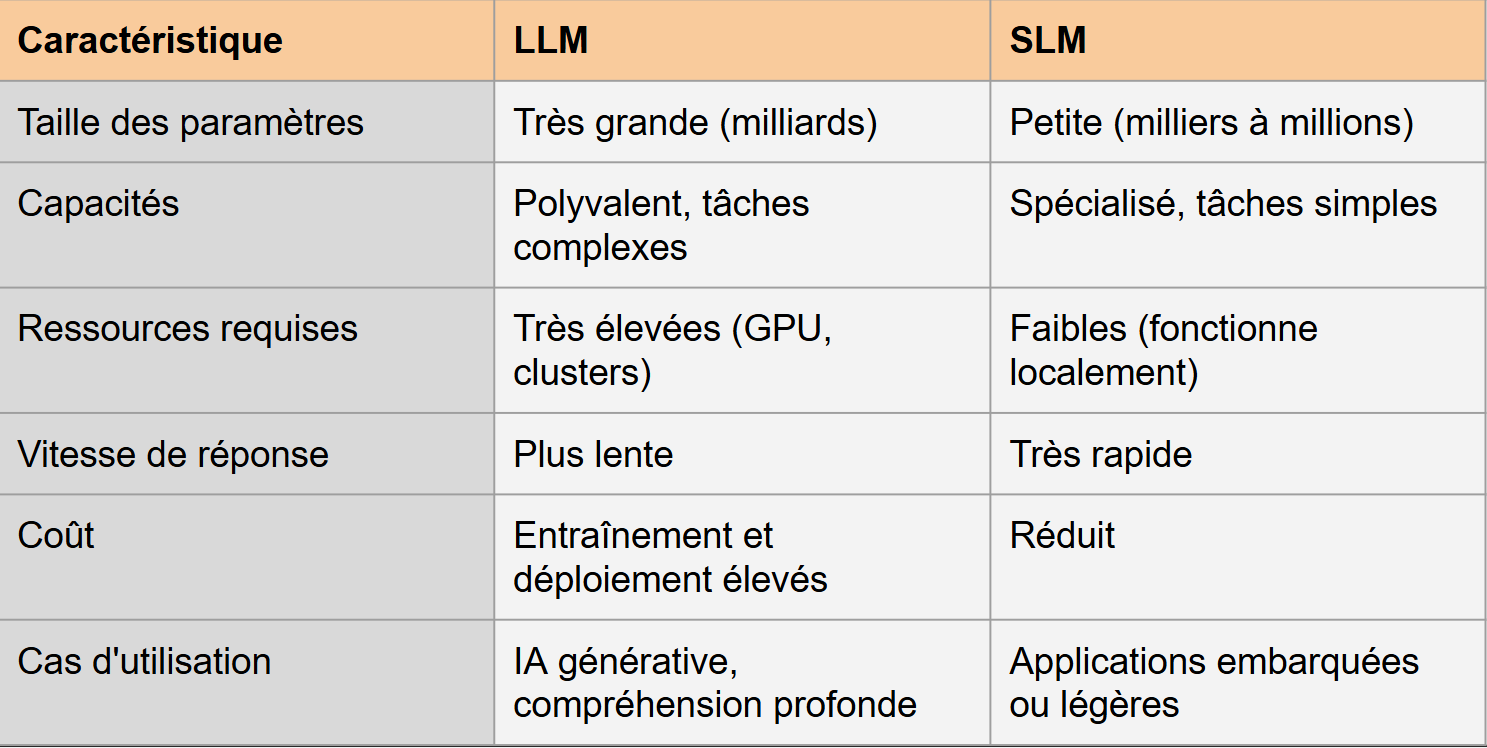
Selon différentes sources comme OpenAI, Microsoft ou Meta, les SLM ont un nombre de paramètres inférieurs ou égal à 7B, tandis que les LLM dépassent cette limite.
NB : Nous utiliserons comme abréviations les notations anglaises, c’est-à-dire M pour millions et B pour milliards (billions).
Comme base d’information, nous allons particulièrement utiliser :
Small Language Models: Survey, Measurements, and Insights Ce document propose une vue d’ensemble des modèles de langage, leurs caractéristiques, et leurs besoins en RAM. Ces informations permettent de choisir des modèles adaptés aux contraintes du projet.
The Costs and Complexities of Training Large Language Models Données cruciales sur les coûts d’entraînement, avec un focus sur les modèles comme GPT-3, ainsi que l’impact financier et énergétique.
The Energy Footprint of Humans and Large Language Models Fournit des estimations détaillées de la consommation énergétique des modèles comme GPT-3 et Llama 3, utiles pour comparer l’efficacité énergétique. On parle ici d’émissions CO² par exemple.!
Scaling Down to Scale Up: A Cost-Benefit Analysis of Replacing OpenAI’s LLM with Open Source SLMs in Production Étudie la faisabilité de remplacer des LLM propriétaires par des modèles open-source, offrant une analyse coûts-bénéfices essentielle.
From Words to Watts: Benchmarking the Energy Costs of Large Language Model Inference Benchmark des coûts énergétiques des inférences pour différents LLM, avec des informations précieuses sur la consommation énergétique par tâche.
HuggingFace Le site web HuggingFace répertorie de nombreux modèles de SLM ou de LLM communautaires ou non. De nombreuses informations y sont présentes sur les coûts énergétiques pour chaque modèle. Cela permet une comparaison relativement fiable entre deux modèles d’une même famille car le traitement reçu est identique.
Ensuite nous avons aussi récupérer de nombreuses informations sur le prix des cartes graphiques, à l’achat ou en location dans le cloud (à l’heure), ce qui nous permet d’avoir des idées du coût engrengé par l’entrainement de certains SLM mais aussi de plus grosses LLM. Il a fallu prendre en compte le nombre d’heures d’entrainement, mais aussi l’infrastructure minimale pour certains modèles (les informations ne sont pas aussi développées pour chacun d’entre eux).
Les coûts par prédiction, en fonction d’un certain nombre de tokens ont aussi été étudié.
Commençons par parler des plus gros modèles actuels.
L’électricité nécessaire pour entraîner GPT-3 a été estimée à environ 1 287 MWh. Les estimations pour Llama 3 sont un peu supérieures à 500 MWh. BigScience Large Open-Science Open-Access Multilingual (BLOOM) a quant à lui consommé 433 MWh. D’autres LLM, dont Gopher et Open Pre-trained Transformer (OPT), auraient utilisé respectivement 1 066 et 324 MWh pour l’entraînement. Ils ont tous plus de 175B de paramètres.
Il est donc important de noter les différences de consommation d’énergie à l’entraînement, même avec des modèles de même taille (nombre de paramètres équivalents). Le ratio entre les deux extrêmes est de 4.
Désormais, parlons de la consommation d’énergie pendant l’utilisation des modèles.
OpenAI avait besoin de 3 617 serveurs HGX A100 de NVIDIA, avec un total de 28 936 unités de traitement graphique (GPU), pour prendre en charge ChatGPT, ce qui implique une demande énergétique de 564 MWh par jour. Comparé aux 1 287 MWh estimés utilisés dans la phase d’entraînement de GPT-3, la demande énergétique de la phase d’inférence semble considérablement plus élevée. En outre, Google a signalé que 60 % de la consommation d’énergie liée à l’IA de 2019 à 2021 provenait de l’inférence.
On entend souvent parler de la différence de consommation d’énergie entre une requête effectuée sur ChatGPT et une simple recherche Google. Un chiffre revient fréquemment dans les études : une requête ChatGPT consommerait au moins 10 fois plus d’énergie qu’une requête Google. Pour donner un exemple plus concret et parlant, SemiAnalysis a estimé que la mise en œuvre d’une IA similaire à ChatGPT dans chaque recherche Google nécessiterait 512 821 serveurs A100 HGX de NVIDIA, totalisant 4 102 568 GPU. Avec une demande d’énergie de 6,5 kW par serveur, cela se traduirait par une consommation électrique quotidienne de 80 GWh et une consommation annuelle de 29,2 TWh. Cette consommation annuelle équivaut à la consommation annuelle totale d’un pays comme le Maroc.
Après avoir discuté de l’inférence globale, parlons plus en détail de l’énergie par inférence, les LLMs se rapproche d’environ 0.00037 kwh contre seulement 0.0001 kWh en local pour les SLM. Et désormais, nous avons aussi des données sur l’énergie par jeton généré. Cela correspond à environ 3.5 Joules pour une longueur de génération maximale de 512 ou 1024 jetons.
De nombreux GPU utilisés dans de anciennes études avaient une puissance maximale de 250W. Un principe serait d’imposer une fausse limite théorique à 70% de la capacité maximale. Cela correspond à réduire ces GPU à 175 W. Cette diminution permettrait donc de diminuer l’énergie totale utilisée de 23 %, mais augmente le temps d’inférence de 6,7 %. Cette perte de performance peut être profitable si les entreprises ne sont pas à quelques jours près pour l’entraînement de leurs modèles.
Cependant, il faut aussi prendre en compte les différences entre la consommation énergétiques des différentes générations des LM. La version 3 de Llama, Llama3-8b est au moins 12 fois plus émettrice que sa version antérieure, Llama2-7b. Ces deux versions ont pourtant un nombre de paramètres équivalents. L’évolution des technologies et des techniques d’entraînement augmentent de façon non négligeables les émissions carbones provoquées.
L’ET-SoC-1 est une puce développée par Esperanto Technologies, conçue pour accélérer les applications d’intelligence artificielle (IA) et de calcul haute performance (HPC). Les coeurs de la puce sont équipés d’une unité vectorielle/tensorielle et de sa propre mémoire cache L1. De plus, ces derniers sont optimisés pour les calculs parallèles massifs.
Le GPU A100 consomme 300W, tandis que la puce ET-SoC 1 ne consomme que 25W, mettant en évidence son efficacité énergétique.
Les métriques TPS/W (tokens par seconde par watt) montrent une grande amélioration pour ET-SoC 1 : Llama 3 : 0,12 sur A100 contre 0,20 sur ET-SoC 1. Phi 3 : 0,12 sur A100 contre 0,40 sur ET-SoC 1.
Ce travail démontre que Phi 3 associé à la puce ET-SoC-1 offre une alternative viable et économe en énergie pour des tâches exigeantes comme la génération de protéines. Il met également en avant la faisabilité d’une transition vers des plateformes non conventionnelles pour l’inférence d’IA, en diminuant les coûts tout en maintenant de bonnes performances.
Désormais nous allons nous attarder sur l’impact financier de l’entraînement et de l’inférence des différents LM.
L’impact financier des LLM est particulièrement important pendant la phase d’entraînement. Un entraînement complet pour GPT-3 coûte environ 1,4 million de dollars. Les coûts d’entraînements pour les plus grosses LLMs peuvent dépasser 4 ou 5 millions de $, alors que cela dépasse rarement les 200 000 $ pour les SLMs.
Cependant, il ne faut pas négliger le coût d’utilisation de ces derniers. En effet, le coût par requête, cela peut aller de 0.1$ à 0.01$ dans le cloud contre moins de 0.001$ en local. Cela correspond au minimum à 10 fois moins.
Pour finir sur l’impact financier, on peut comparer le nombre de GPU nécessaire pour l’utilisation de LLM par rapport à un SLM. Llama 65B nécessite 8 GPU V100 pour des inférences viables contre seulement 1 seul pour le modèle 7B. Cela permet de réduire considérablement les prix nécessaires pour l’achat du hardware, ou bien de la location à l’heure sur le Cloud.
La technique de la distillation a pour but d’utiliser les connaissances d’un LLM, et d’en distiller les connaissances. Cela va permettre d’entraîner un modèle plus léger sur la base des connaissances d’un modèle puissant. Pour éviter des erreurs de prédiction, notamment à cause du surentraînement, on ne réutilise pas les données d’apprentissage initial. Ainsi, le modèle le plus puissant va permettre de valider ou non les réponses de son élève (le SLM). Cette technique de fine-tuning permet donc de récupérer et surtout de reproduire les distributions de probabilités de son maître. Dans notre exemple, Llama2-7B, qui a appris avec cette technique, a un bilan carbone 10 fois inférieur vis-à-vis de la version 70B.
Cependant cette technique présente deux défaults notables. Le premier est qu’il faut déjà avoir un LLM puissant, coûteux en énergie à l’entraînement. Pour un modèle comme Llama2-70B, cela correspond à près de deux millions d’heures GPU d’entraînement (~300 tonnes éq. CO²). Et cela reste bien loin des modèles les plus puissants actuellement, comme GPT4 et ses 54 000 000 d’heures GPU. Le second est qu’il faut prendre en compte qu’un modèle puissant peut être coûteux à l’inférence. Il est donc toujours préférable de prendre en considération cet aspect pour bien choisir son LLM maître. Le troisième est que cette technique réclame de grandes quantités de données pour obtenir des performances équivalentes à des modèles de très grandes tailles, comme LLama 3 70B. D’ailleurs, comme les chercheurs se sont aperçus que l’usage d’un plus gros volume de données de meilleure qualité est bénéfique en matière de performances, les entraînements sont plus longs, et donc plus consommateurs.
Graphique des moyennes des expériences réalisées par Google Research
Le fine-tuning est une technique utilisée pour adapter des modèles de langage préentraînés à des tâches spécifiques tout en exploitant des ressources limitées.
Le fine-tuning consiste à prendre un modèle préentraîné, tel que BERT ou T5, et à ajuster ses paramètres en utilisant un jeu de données annoté pour une tâche spécifique. Cela permet au modèle de se spécialiser tout en conservant les connaissances générales acquises durant son préentraînement. Cette méthode est particulièrement utile pour des applications nécessitant des performances rapides et une empreinte mémoire réduite.
Cependant, le fine-tuning a ses limites. Il dépend fortement de la qualité et de la quantité des annotations humaines, qui sont coûteuses et chronophages à produire. Malgré ces quelques éléments compliqués à mettre en oeuvre, le fine-tuning reste une approche clé pour exploiter les SLM dans des contextes nécessitant une efficacité en ressources.
Hugging Face Spaces : Pour explorer les modèles, visualiser leurs performances (latence, empreinte carbone). SLaM (Small Language Model Assessment) : Plateforme pour tester les SLM, comparer leurs coûts et performances. Optimum/LLM Performance Leaderboard : Pour des comparaisons entre modèles concernant l’empreinte carbone et les besoins matériels. Calculatrices en ligne de coûts d’infrastructure comme TensorDock, OVHCloud, etc., pour estimer les coûts financiers.
Des outils pour utiliser en local des SLM come GPT4All ou LMStudio. Nous développerons aussi nos propres outils, notamment pour mesures de la consommation énergétique sur macOS afin de réaliser une expérimentation avec l’utilisation de SLM.
Phi 3 et Llama 3 : Choisis pour leur efficacité énergétique (réduction d’énergie grâce à ET-SoC-1). SmolLM : Modèle léger avec un faible coût énergétique et mémoire. StarCoder : Pertinents pour les applications nécessitant une génération de code. Données d’entraînement : Prise en compte des tailles de batchs, nombre de tokens utilisés, et empreinte carbone par paramètre.
Les raisons de ces choix incluent : La viabilité énergétique : Focus sur les modèles à basse consommation énergétique comme Phi 3. Réduction des coûts : Modèles légers et open-source pour minimiser les dépenses. Adaptabilité : Modèles offrant des options de fine-tuning ou d’adaptation à des tâches spécifiques.
Étant donné le manque d’informations que nous avons sur les SLM, nous avons décidé de réaliser une expérimentation afin d’en obtenir.
Pour cela, nous avons mesuré la consommation énergétique d’un SLM exécuté localement, afin d’évaluer son efficacité en comparaison avec les Large Language Models (LLM) exécutés dans le Cloud. Nous avons cherché à avoir une méthodologie proche de celle utilisée dans l’étude From Words to Watts: Benchmarking the Energy Costs of Large Language Model Inference afin de pouvoir comparer les résultats.
L’expérimentation s’appuie sur le dataset Alpaca, un ensemble d’instructions textuelles conçu pour le fine-tuning de modèles de langage. Nous avons sélectionné 4096 entrées pour assurer un échantillon représentatif, cependant nous avons limité le nombre d’instructions traitées par modèle à 256, afin de réduire le temps d’exécution. Trois variantes de modèles sur GPT4All ont été testées : Llama 3.2 1B Instruct, Llama 3.2 3B Instruct et Llama 3 8B Instruct. Ces modèles sont exécutés localement sur un MacBook Pro 16-inch 2021 (M1 Pro, 16 Go RAM, macOS Sequoia 15.2), en utilisant l’API Metal de macOS pour l’inférence.
La méthodologie adoptée repose sur plusieurs étapes. Un premier script permet de récupérer les données et de préparer les entrées pour l’inférence. Un second script exécute les requêtes en local via l’API de GPT4All, mesure le temps d’exécution et collecte les données de consommation énergétique via l’outil powermetrics. Ces mesures permettent d’analyser la puissance consommée par le GPU ainsi que l’énergie totale utilisée pour l’inférence.
Les résultats sont ensuite visualisés sous forme de graphiques afin de comparer le temps d’inférence aux besoins énergétiques, d’évaluer les performances en mots/s et tokens/s, et d’identifier les variations de consommation énergétique en fonction des modèles.
Plusieurs axes d’amélioration sont envisagés, notamment la comparaison avec d’autres modèles, l’expérimentation sur différentes configurations (batch size, température, utilisation exclusive du CPU), ainsi que l’optimisation de l’utilisation des ressources matérielles pour minimiser la consommation énergétique.
L’expérimentation est expliquée plus en détail directement dans son répertoire. Vous trouverez plus d’informations ici.
Voici une liste de graphique qui mettent en forme les résultats de nos études. Ensuite nous étudierons et expliquerons l’enjeu et l’intérêt de chaque graphique vis-à-vis de l’enjeu financier et énergétique des SLM par rapport aux LLM.
La quasi-totalité des graphiques ci-dessous ont été réalisé par nos soins. Ceux ne l’ayant pas été sont précisés.

Figure 1 - Consommation d’énergie & émissions de CO² en fonction du nombre de paramètres
L’intérêt ici est de voir les différences entre les consommations d’énergies, les émissions CO2 de très grosses LLMs (environ 175B de paramètres). La grille énergétique utilisée est aussi très importante et on voit pour deux modèles plus ou moins équivalent en performances comme GPT-3 et BLOOM une réduction de 3x pour l’énergie et 10x pour les émissions CO². On voit donc la différence d’utiliser du nucléaire ou des énergies fossiles pour alimenter les GPUs utiles aux entraînements des modèles.

Figure 2 - Energy used and CO²emissions by SLM_LLM (BLOOM)
L’énergie utilisée par les différents modèles n’est pas proportionnelle au nombre de paramètres. Mais cela montre, en regardant aussi les résultats de performances des différents modèles, que de créer de nouveaux modèles toujours plus gros et en masse n’est pas forcément utile. Créer de petits modèles plus performants sur des sujets spécifiques peut être un objectif pour les entreprises, améliorant leur consommation énergétique tout en faisant baisser les coûts globaux.

Figure 3 - Parameters, memory footprint and training tokens by SLM/LLM
SmolLM-135M et SmolLM2-135M ont une empreinte mémoire et un nombre de paramètres très faibles, ce qui les rend légers. Starcoder2-15b est le modèle le plus volumineux avec une empreinte mémoire importante et un grand nombre de tokens pour l’entraînement. On remarque une corrélation générale : plus un modèle a de paramètres, plus son empreinte mémoire et ses besoins en tokens augmentent.

Figure 4 - Memory ratio by SLM_LLM size
SmolLM2-135M affiche le ratio mémoire/paramètres le plus élevé, ce qui signifie qu’il utilise davantage de mémoire par paramètre comparé aux autres modèles. Starcoder2-15b a un ratio mémoire/tokens beaucoup plus important, ce qui reflète une plus grande consommation mémoire par token. Cela indique que les petits modèles comme SmolLM sont très efficaces en termes de mémoire, tandis que des modèles volumineux comme Starcoder2-15b deviennent coûteux en ressources mémoire par token.

Figure 5 - Coût ($) pour 1K token vs. Nombre de paramètres (B)
Le coût par token augmente de manière quasi linéaire avec le nombre de paramètres. Les modèles plus petits (SmolLM) ont un coût négligeable ou très faible, tandis que les modèles plus grands comme Starcoder2 deviennent nettement plus coûteux. Ce graphique souligne l’importance d’optimiser la taille du modèle pour les projets où le budget est limité. Il faut prendre en compte le manque de données pour des LLMs plus importantes ce qui peut théoriquement légèrement fausser le résultat et/ou résulter en imprécisions.

Figure 6 - Énergie consommée en fonction du nombre de paramètres du modèle (pour 1m de tokens)
Ce shéma nous permet de mettre en avant la relation entre le nombre de parametres d’un model et l’energie qu’il consomme. Aussi, nous pouvons voir l’influence qu’a le type d’unité de calcul utilisée sur l’energie consommée. Ainsi, nous pouvons voir que pour deux modèles de la même taille, l’unité de calcul aura une incidence plus ou moins importante. En revanche, tous les processeurs ne pourront pas entraîner tous les modèles. Par exemple, il n’existe pas de modèles a plus de 11 milliards de paramètre.

Figure 7 - Ratio des coûts de location et d’achat pour l’entrainement de différents modèles
Sur HuggingFace, une quantité de hardware nécessaire pour l’entrainement est précisé pour que cela soit optimal. On parle par exemple de GPU comme les A100 ou les H100. Les prix de locations sont donc calculés à l’heure (sans que l’on ai le nombre d’heures nécessaires pour avoir un entrainement complet du modèle). On voit donc un ratio d’au moins 15 pour le prix de location ou d’achat entre le plus petit modèle de 135M de paramètres et celui de 15B.

Figure 8 - Relation entre le nombre de paramètres et le coût en CO²
On voit la séparation entre SLM et LLM à 7B de paramètres, limite définie précédemment. Les coûts en C0² augmentent de façon exponentielle à partir de cette limite, tandis que pour la plupart des SLM, nous avons des coûts presque négligeable.

Figure 9 - Gas emissions by LLM
On retrouve ici un rapport de 15 entre le plus gros modèle et le plus petit. Il faut se demander si utiliser toujours le plus gros modèle même pour des questions simples comme des recettes de cuisine demeure pertinent. Il faut adapter le LLM/SLM que l’on choisit au niveau de difficulté des requêtes, et du degré de précision que l’on souhaite recevoir.
Suite à notre expérimentation, nous allons analyser les résultats sur l’utilisation de SLM en local. Vous trouverez les différents résultats que nous avons pu obtenir, avec des comparaisons des données provenant de l’étude From Words to Watts: Benchmarking the Energy Costs of Large Language Model Inference [1] lorsque c’est possible.
L’étude utilise des modèles de Llama 1, nous utilisolns des modèles de Llama 3 et 3.2. Les comparaisons faites ne doivent pas être prises pour acquises, mais elles permettent de nous donner une idée.
Nous pouvons d’abord commencé par analysé le taux de réponse des SLM vs LLM.

Figure 10 - Data per second from study [1]
Dans l’étude, l’inférence des LLM dans le Cloud permet d’avoir respectivement 1100, 800 et 300 tokens par seconde pour les modèles 7B, 13B et 65B sur un carte A100.

Figure 11 - Moyenne de tokens par seconde par SLM en local
Pendant notre expérimentation avec des SLM en local, nous pu observer une sortie de 100, 55 et 30 tokens par seconde pour les modèles 1B, 3B et 8B.
La différence est considérable entre des LLM dans le Cloud et des SLM en local. Les LLM génèrent 10 fois plus de tokens pour des modèles 10 fois plus gros. Pour un modèle d’environ la même taille (7B et 8B), l’inférence dans le Cloud est 36 fois plus performante.
Un LLM exécuté dans le Cloud est donc beaucoup plus rapide qu’une SLM exécuté en local sur un Macbook M1 Pro. Mais cela n’est pas le seule critère, nous pouvons aussi nous intéresser à l’énergie utilisée.

Figure 12 - Inference energy per second from study [1]
Dans le Cloud, si nous prenons seulement le modèle 7B sur le GPU le plus puissant (A100), nous avons une consommation d’environ 280 joules.

Figure 13 - Moyenne d’énergie consommée par le GPU par inférence
En local, l’énergie moyenne consommé par inférence sur le modèle 8B est de 360 Joules.
Pour un modèle très similaire, la consommation électrique en local est donc supérieur. Cela peut s’expliquer par le fait que l’exécution sur des GPU Nvidia (d’autant plus les A100 et V100) est très optimisée, comparé à une exécution en local. De plus les GPU ont beaucoup plus de mémoire dans le Cloud.
L’inférence en utilisant des modèles plus petits en local permet bien sûr d’avoir des consommations électriques moindes. Cependant, il faudrait alors prendre en compte l’usage que l’on veut faire du modèle pour savoir si cela est envissageable à mettre en place.
Pour finir, nous avons 2 autres types de données sur l’utilisation de SLM en local.

Figure 14 - Puissance moyenne du GPU par modèle
Ici nous pouvons observer la puissance moyenne du GPU lors d’inférences pour chaque modèle. Plus le modèle est conséquent, plus la puissance est élevée. Pour le modèle 8B, nous approchons de la limite du Macbook M1 Pro en terme de puissance GPU.

Figure 15 - Temps moyen d’inférence en local par SLM
En local, la taille du modèle impacte fortement le temps d’inférence. Pour le modèle 1B, cela est très convenable en environ 4 secondes. Par contre pour le modèle 8B, un temps de réponse de 20 secondes commence à être dérangeant pour un utilisateur.
Dans l’ensemble des graphiques présentés ci-dessus, nous voyons que les consommations énergétiques à l’entraînement de petits modèles comme les SLM sont drastiquement réduits. On obtient une énergie consommée qui est 10x inférieure entre le modèle 175B et celui 7B (cf graphique 1). Les émissions CO² sont aussi réduites considérablement : réduite par 15 entre le modèle Llama 405B et sa version à la limite du SLM, la 8B (cf dernier graphique).
Le graphique 5 montre aussi une augmentation exponentielle des émissions au moment où les paramètres dépassent les 7B.
Attention, certains graphiques (rouge & bleu) nous montrent que le ratio Mémoire/Token est plus importante pour les SLM que pour les LLM. De ce point de vue il est plus intéressant d’avoir un nombre de paramètre plus élevé.
Il est toujours important de remarquer que l’empreinte mémoire est toujours bien plus faible pour les SLM que pour les LLM, car cela dépend fortement du nombre de paramètre, bien que ce ne soit pas proportionnel.
Pour BLOOM, le modèle 175B a consommé environ 430MWh contre seulement 50MWh pour le modèle 6B, qui correspond donc à un SLM. BLOOM est un modèle crée par HuggingFace (entreprise franco-américaine) et le CNRS, qui a été entraîné dans la région parisienne.
En France, ce prix s’élève à environ à 200 € pour les ménages contre 150€ pour les tarifs de gros.
Cela revient environ à 64 500€ pour le plus gros modèle, contre seulement 7500€ pour le SLM. Cela représente une économie de presque 90% pour un SLM vis-à-vis d’un LLM de la même famille.
Suite à l’expérimentation que nous avons faites et les résultats que nous avons pu observer, surtout en comparaison avec les LLM dans le Cloud, il est difficile de tirer une conclusion unanime.
Pour un modèle d’une même taille, il est préférable de l’utiliser dans le Cloud étant donné l’optimisation qui sera proposée. Cependant, si la taille n’est pas un facteur clé dans le choix et que l’on peut choisir un modèle assez petit en nombre de paramètre, alors l’utilisation en local peut s’avérer pertinente. Elle serait largement moins consommatrice d’énergie.
D’un point de vue financier, si l’utilisation d’un SLM en local remplace un LLM dans le Cloud qui possède un vrai coût (abonnement etc.), alors le SLM en local devrait être largement gagnant, étant donné que nous paierons ici simplement le coût de l’énergie en plus consommé alors qu’un LLM dans le Cloud doit aussi prendre en compte les coûts d’infrastructure etc.
Nos résultats nous ont permis de valider certaines hypothèses de départ.
Notre première hypothèse était la suivante : un SLM, grâce à sa taille réduite, consommerait nettement moins qu’un LLM. Cette hypothèse est validée, notamment par les graphiques 2, 3, 6, 8 et 9. Même si la relation d’ordre n’est pas complètement proportionnelle, un SLM réduit considérablement l’énergie consommée à l’entraînement, à l’inférence, mais aussi ses émissions CO².
Notre seconde hypothèse était le fait que les SLM permettent de réduire considérablement les coûts financiers des entreprises. Cette hypothèse est aussi validée par les graphiques 5 et 7. Nous avions relevé un ratio de 15 entre le prix de location ou d’achat d’un SLM et d’un LLM de la même famille. Cela ne concerne pas uniquement la phase d’entraînement, mais aussi celle de l’inférence.
Notre dernière hypothèse était que les SLM peuvent être utilisés en local contrairement aux LLM, et ce avec une configuration d’une personne lambda. Cela permet de réduire à la fois les coûts financiers et énergétiques. La première partie de cette hypothèse est vraie. La plupart des SLM tournent aisément en local. Cependant, avec les avancées technologiques rapides, des entreprises comme NVIDIA ont développé des LLM capables de tourner sur des configurations locales. La seconde partie est quant à elle fausse. Selon l’expérimentation menée, utiliser un SLM localement ne permet pas de réaliser des économies d’énergies par rapport au Cloud. La consommation augmente d’environ 25% selon nos résultats. Cela met en avant que les SLM sont bien plus économiques que les LLM, mais faire tourner en local ces petits modèles s’apparente à une fausse bonne idée. Cependant, avoir un SLM en local permet tout de même de ne pas être dépendant du Cloud.
Il est important de note qu’il est difficile de généraliser nos résultats ou ceux des études. Il faut prendre du recul sur les résultats que l’on fourni car il y a de nombreux facteurs à prendre en compte comme le hardware, la taille des modèles, la taille, les familles, le lieu et l’heure d’entraînement et d’exécution des LLM/SLM.
L’émergence récente des modèles de langage bouleverse notre rapport aux technologies numériques et soulève des questionnements fondamentaux.
Ces systèmes intelligents, capables de générer du texte, de comprendre et de traduire des informations complexes, nous invitent à réfléchir sur leurs implications concrètes. Comment intégrer ces outils de manière responsable, en tenant compte de leurs coûts énergétiques et environnementaux ? Quels sont les véritables impacts de ces technologies sur nos métiers, nos processus de création et nos interactions sociales ? Au-delà de leurs performances techniques, ces modèles interrogent notre capacité à maîtriser des outils dont la puissance est en augmentation constante.
Entre risque et innovation, les LM représentent une nouvelle ère numérique où l’intelligence artificielle est devenu un membre à part dans notre quotidien.
Utilisation de HuggingFace et de leur API (modèles, base de données & spaces). Cela permet de récupérer un grand nombre de données sur les SLM et LLM dans le but de réaliser des graphiques.
Réalisation d’une expérience avec GPT4All et Powermetrics (macOS) afin d’avoir des données sur le coût financier et environnemental de l’utilisation d’un SLM en local.
Nos codes, résultats bruts et expérimentations sont disponibles ici : Team E - Assets.
SmolLM - blazingly fast and remarkably powerful https://huggingface.co/blog/smollm
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone https://arxiv.org/abs/2404.14219
Llama 2: Open Foundation and Fine-Tuned Chat Models https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
Tutorial - Small Language Models (SLM) https://www.jetson-ai-lab.com/tutorial_slm.html
SmolLM2-135M https://huggingface.co/HuggingFaceTB/SmolLM-135M
Petits modèles https://www.lemagit.fr/conseil/IA-generative-petit-modele-petit-bilan-carbone?utm_source=chatgpt.com
Distillation https://research.google/blog/distilling-step-by-step-outperforming-larger-language-models-with-less-training-data-and-smaller-model-sizes/
Distillation de connaissance https://techtalkwithsriks.medium.com/building-small-language-models-using-knowledge-distillation-kd-6825ce2f6d24
https://en.wikipedia.org/wiki/GPT-2
https://en.wikipedia.org/wiki/GPT-3
https://en.wikipedia.org/wiki/GPT-4
The Memo - Special edition: Claude 3 Opus https://lifearchitect.substack.com/p/the-memo-special-edition-claude-3
From Words to Watts: Benchmarking the Energy Costs of Large Language Model Inference https://ar5iv.org/html/2310.03003
Energy Footprint Of LLMs https://cacm.acm.org/blogcacm/the-energy-footprint-of-humans-and-large-language-models/
Measuring and Improving the Energy Efficiency of Large Language Models Inference https://ieeexplore.ieee.org/document/10549890
The Costs and Complexities of Training Large Language Models https://deeperinsights.com/ai-blog/the-costs-and-complexities-of-training-large-language-models
Starcoder2 https://huggingface.co/docs/transformers/main/model_doc/starcoder2
BLOOM’s energy consumption https://www.jmlr.org/papers/volume24/23-0069/23-0069.pdf
The growing energy footprint of artificial intelligence https://www.cell.com/joule/fulltext/S2542-4351(23)00365-3
GPT 4 infos https://ai-side.com/fr/news/nouveau-leak-gpt-4-decryptage
Large Language Models (LLMs) vs. Small Language Models (SLMs) https://www.rackspace.com/blog/large-language-models-llms-vs-small-language-models-slms
https://portal.azure.com/#view/Microsoft_Azure_Compute/SpecPickerV2Blade
SLM vs LLM https://www.redhat.com/en/topics/ai/llm-vs-slm
Protein SLM vs LLM https://arxiv.org/html/2411.05966v1
Open LLM HuggingFace Leaderboard https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard#/
Open LLM HuggingFace Performance Leaderboard https://huggingface.co/spaces/optimum/llm-perf-leaderboard
https://www.tensordock.com/gpu-a100
https://getdeploying.com/buildai
https://getdeploying.com/runpod
https://www.hyperstack.cloud/a100
https://www.amazon.com/PNY-A100-80GB-Graphics-Card/dp/B0CDMFRGWZ
https://www.senetic.fr/product/4X67A76715?srsltid=AfmBOop7MmoXG1xHlq-iYYTsDcxJmYq-wNc4VuxjoTTWoyv7JF5FMZU2
https://viperatech.com/shop/nvidia-a100/?srsltid=AfmBOopcLeK3VklnPCrusxmnGGw687Yg_pF4AJcO4BFx39VpPqzl_lLl
https://www.runpod.io/gpu/h100-pcie
https://www.hyperstack.cloud/h100-pcie
https://www.amazon.com/H100-Graphics-Accelerator-900-21010-0000-000-Warranty/dp/B0CGL976H5
https://www.boston-it.fr/gb/cartes-gpu/17787-nvidia-h100-80gb-pcie-50-x16-double-width-passive-cooling.html
US Energy Cost https://www.eia.gov/electricity/monthly/update/wholesale-markets.php
Coût de l’électricité en France https://www.totalenergies.fr/particuliers/electricite/prix-de-l-electricite/prix-du-kwh-d-electricite/consommation-d-energie-prix-du-kwh-d-electricite?utm_source=chatgpt.com
Info énergie https://selectra.info/energie/electricite/prix.
![]()
