janvier 2024
Nous sommes 4 étudiants à Polytech Nice Sophia en spécialisation Architecture Logicielle.
Les architectures en microservices sont devenues la norme dans l’industrie. Avec la montée en puissance des applications cloud-native et de la demande croissante pour des systèmes agiles et évolutifs, de nombreuses entreprises se tournent vers cette approche pour développer et déployer leurs applications. Dans ce contexte, notre projet vise à fournir une analyse statique des projets en microservices, permettant d’évaluer la qualité de leur architecture. Cette analyse offrira des informations précieuses pour garantir que les projets en microservices sont conçus en suivant des principes de conceptions fiables et démontre une architecture qui tend à être bonne.
Une architecture en microservices repose sur plusieurs bons principes. Les patterns tels que la réplication des bases de données, la répartition de charge, le déploiement individualisé des microservices permettent d’avoir un système distribué plus résilient et tolérant aux pannes. L’étude de ces patterns et outils nous donne une idée sur la qualité du projet. D’où notre question générale :
Comment l’étude des patterns et des outils de développement permet d’évaluer une architecture en microservice ?
Les sous-questions de notre problématique sont les suivantes :
La collecte d’informations pour notre étude se concentre sur des articles scientifiques et des publications de référence dans le domaine des architectures microservices. Ces documents, issus de revues spécialisées et de conférences technologiques, fournissent un aperçu des dernières recherches, tendances et meilleures pratiques dans la conception et l’implémentation des microservices. L’analyse de ces articles nous permet de définir des critères objectifs et mesurables pour évaluer la qualité architecturale des projets en microservices.
Nous avons retravaillé nos objectifs à plusieurs reprises. Au départ, nous avions la prétention de détecter correctement un maximum de pattern et de brique afin d’avoir le plus de métrique possible sur un projet.
Après plusieurs discussions entre nous et avec les enseignements, nous nous sommes rendu compte de l’ampleur d’un tel objectif.
Tout d’abord, les projets sont écrits dans un certain langage, et vouloir tout détecter en prenant en considération tous les langages possibles n’était pas faisable dans le temps donné.
Ensuite, repérer un pattern n’est pas une tâche simple, car ces modèles existent pour résoudre des problèmes bien définis. Cependant, souvent, nous adaptons ces patterns au contexte spécifique d’un projet. Ainsi, il est crucial que les outils soient capables de comprendre cette intuition et l’adaptation par rapport au problème. De plus, ils doivent être en mesure de reconnaître le problème lui-même. Par exemple, nous avions pour ambition de détecter le pattern CQRS, mais il répond à un problème spécifique. La simple détection de ce pattern par nos outils ne garantit pas nécessairement une utilisation correcte et justifiée. Le défi réside dans la détection des décisions prises en fonction de l’intuition humaine. Bien que la reconnaissance technique de fragments de pattern soit réalisable, la détection du contexte, de l’adaptation et de la pertinence de son utilisation représente un travail complexe.
En résumé, nous priorisons les patterns et briques architecturales les plus fréquemment mentionnés dans la documentation, privilégiant ceux qui peuvent être développés avec une dépense minimale tout en offrant une valeur maximale pour répondre à notre question.
Notre analyse portera sur les projets déployés avec la technologie docker-compose. En effet, nous avons remarqué que cette technologie est beaucoup utilisée dans les architectures microservices. Même si les grands projets utilisent des technologies avancées comme le cloud et Kubernetes en production. La plupart des projets open source utilisent docker-compose comme outil de pré-production pour tester l’application en local. Les repositories GitHub disposent dans la plupart des cas d’un fichier docker compose.
Par conséquent, l’analyse statique des fichiers docker-compose va permettre d’extraire des bons indices sur l’architecture du projet en question.
De plus, nous avons décidé de chercher d’autre patterns qui ne sont pas entièrement présents dans le fichier docker compose et qui nécessitent une analyse du code source. Voici les patterns et briques analysées par nos outils :
Dans le cadre de notre étude, nous avons mis en œuvre une approche systématique pour la collecte de projets open source en utilisant l’API GitHub. Cette méthode s’est articulée autour de trois étapes principales : le scrapping par mot-clé, le filtrage visuel, et la gestion des faux positifs.
Scrapping par mot-clé : Notre premier pas a consisté à développer des outils pour rechercher automatiquement des projets GitHub basés sur des microservices. En utilisant des mots-clés spécifiques comme “microservices”, “Docker”, “Kubernetes”, “Kafka”, “RabbitMQ”, et autres termes associés, nous avons pu scanner une vaste gamme de dépôts. Cette technique de scrapping par mot-clé a été essentielle pour débuter notre recherche et identifier un grand nombre de projets potentiellement pertinents.
Filtrage visuel : Bien que l’utilisation de l’API GitHub ait été efficace pour rassembler une liste exhaustive de projets, nous avons rencontré le défi majeur de trier cette multitude de résultats. Pour ce faire, nous avons adopté une approche de filtrage visuel. Cette étape a impliqué un examen manuel des projets récupérés afin de déterminer leur pertinence réelle par rapport à notre sujet d’étude. Notre équipe a minutieusement passé en revue les projets, en évaluant des aspects tels que la structure du code, la documentation, et l’utilisation effective des technologies de microservices mentionnées.
Gestion des faux positifs : Une difficulté notable rencontrée lors de ce processus a été le volume élevé de faux positifs. En d’autres termes, de nombreux projets identifiés par l’API GitHub en utilisant nos mots-clés ciblés ne répondaient pas réellement aux critères d’une architecture en microservices. Ces faux positifs provenaient souvent de l’utilisation superficielle des mots-clés dans des contextes non-pertinents, de projets abandonnés ou mal documentés, ou de dépôts qui, bien qu’utilisant certaines technologies associées aux microservices, n’implémentaient pas une architecture microservice authentique. Par conséquent, le filtrage manuel et visuel a été un élément crucial pour affiner notre sélection et aboutir à un ensemble plus restreint et qualitatif d’environ cinquante projets qui correspondaient véritablement à nos critères d’analyse.
Le développement de nos outils se base sur une analyse approfondie des structures des répertoires des projets en microservices. Nous avons conçu des scripts automatisés qui scannent et interprètent la structure des répertoires, les fichiers de configuration et le code source. Ces outils utilisent des algorithmes de reconnaissance de motifs pour identifier les patterns architecturaux courants dans les microservices, tels que la conteneurisation avec Docker, ou encore l’implémentation de la réplication maître-esclave. L’objectif est de fournir une évaluation rapide et précise des caractéristiques clés d’une architecture microservices.
Cet outil a pour responsabilité de détecter si un docker-compose existe dans le projet, et s’il existe, de récupérer son contenu sous format yaml afin de pouvoir l’utiliser dans les différentes analyses ci-dessous. Cet outil est capable de récupérer également les noms des services et images du docker compose.
S’il n’y a pas de docker compose, l’analyse prend fin. La plupart de nos outils fonctionnent grâce au docker compose. S’il n’existe pas, nos outils ne répondent plus à la question.
Après avoir détecté le docker compose, il faut absolument trouver que nos microservices sont bien conteneurisés et déployés indépendement. Cet outil permet de trouver les images qui sont construites lors du build de l’application et ensuite les comparer avec les répertoires. Nous avons remarqué que dans la plupart des projets les noms des services déployés avec docker et les noms des répertoires de chaque microservice sont les mêmes.
Par exemple dans ce projet https://github.com/Microservice-API-Patterns/LakesideMutual. Nous constatons que le service customer-management-backend et son répertoire (directory) ont le même nom.
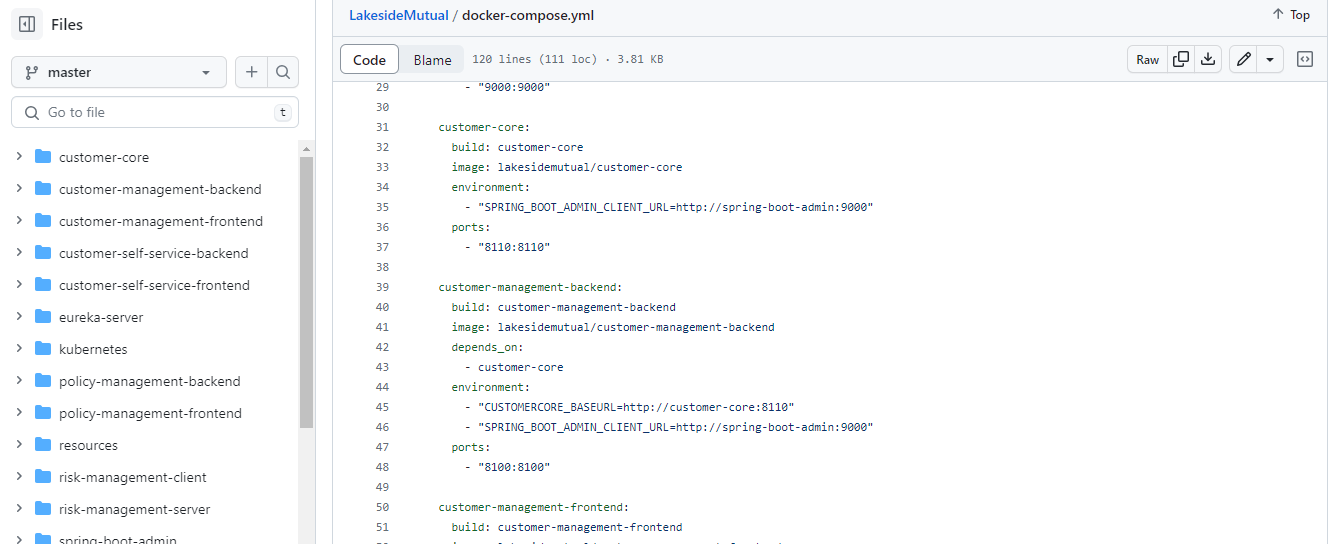
Alors, nous avons basé notre analyse sur cette remarque pour confirmer que les microservices sont déployés indépendamment.
La sortie de l’outil va retourner un booléen qui confirme ou pas le déploiement individualisé des microservices.
Cet outil détecte dans le compose la présence de Kafka ou de RabbitMQ dans les images du docker compose. Il existe d’autres technologies pour gérer les événements, mais nous avons considéré ces deux technologies, car elles sont les plus utlisées.
La sortie de cet outil est un booléen qu’exprime la présence ou non d’une technologie de gestion d’événement.
Cet outil détecte la présence du mot-clé “gateway” dans les images du docker compose. Il parse aussi les dossiers à la racine pour détecter si le mot-clé “gateway” est présent.
La sortie est un booléen qui exprime la présence ou non d’une gateway dans le projet.
En explorant plusieurs projets open source, nous avons remarqué que le pattern master-slave est souvent implémenté dans le docker compose. Nous avons constaté la présence de deux images, une pour le nœud master et un autre pour le slave.
Cet outil détecte la présence des mots-clés [‘master’, ‘slave’, ‘replica’] dans le docker compose. S’il détecte l’un de ces mots, nous considérons qu’il y a un pattern de réplication.
La sortie est un booléen qui exprime la présence ou non d’un pattern de replication des données.
La présence de ce pattern améliore la qualité de l’architecture en microservice. En effet, ce pattern est souvent utilisé dans un contexte CQRS (Command and Query Responsibility Segregation), la base de données slave sert dans ce cas pour la lecture des données à travers un microservice, tandis que le nœud master est utilisé pour l’écriture/modification des données. Le pattern CQRS est difficile à détecter par analyse automatique puisqu’il dépend fortement du langage de programmation et technologies. Nous ne l’avons pas traité dans nos outils à cause des contraintes de temps.
Cet outil cherche à déterminer le nombre de dépendance des services dans les bases de données. L’évaluation effectuée par cet outil donne. Idéalement, chaque base de données devrait être utilisée par un seul service, favorisant ainsi une architecture modulaire, facilement maintenable et scalable.
Pour réaliser cette évaluation, l’outil utilise plusieurs méthodes :
Analyse des depends_on dans le Docker Compose : en examinant les déclarations depends_on, l’outil identifie le nombre de dépendances entre les services et les bases de données.
Analyse textuelle : si la première méthode ne permet pas de déterminer les dépendances, l’outil parcourt l’ensemble des fichiers du projet pour repérer les occurrences du nom des services. Le nombre de répertoires distincts à la racine du projet est alors comptabilisé comme le nombre de dépendances. Cette méthode est indépendante du langage de programmation, considérant les fichiers comme du texte brut. Elle prend en compte le DNS Docker ou le nom du service pour établir les connexions entre les services et les bases de données.
Analyse des variables d’environnement : en complément de la méthode précédente, lorsque le parsing des fichiers ne révèle aucune dépendance pour une base de données, l’outil recherche le nom de cette base dans les variables d’environnement du fichier Docker Compose pour déterminer d’éventuelles connexions non détectées par l’analyse textuelle.
Ces analyses combinées offrent une évaluation approfondie des dépendances entre services et bases de données, facilitant ainsi la conception d’une architecture logicielle optimale.
La sortie peut prendre plusieurs forme. Si chaque db est utilisé par un microservice, alors la valeur de retour exprime que le principe analysé est respecté dans l’absolu. Si toutes les dbs ont des dépendances supérieures à 1, alors la sortie exprime la non-conformité au principe d’architecture microservice. Si au moins une dbs n’est pas égale à 0 dans le nombre de dépendance, alors la sortie exprime la nécéssité de l’observation de l’utilisateur.
La base de données MongoDB est trop utilisée dans les projets microservices, elle permet d’avoir de la réplication en lecture sur plusieurs nœuds. La base de données MongoDB est trop utilisée dans les projets microservices, elle permet d’avoir de la réplication en lecture sur plusieurs nœuds.
Notre analyse va chercher l’argument “–replSet rs0” dans les commandes du docker compose. Cette commande permet de démarrer la base de données en tant que réplicat.
La sortie de l’outil est un booléen qui exprime la présence ou absence du pattern de réplication en lecture avec Mongo DB.
La répartition de charge est un principe important dans les systèmes distribués et microservices. La scalabilité des microservices permet d’avoir une bonne résistance à la charge et par la suite des bonnes performances. La détection de ce pattern ne dépend pas directement du langage de programmation, mais plutôt de la technologie de LoadBalacing utilisée. Les technologies les plus utilisées dans le cadre du déploiement avec docker-compose sont :
1) nginx : utilisé comme un serveur web, reverse proxy ou bien loadbalancer. 2) traefik : orchestrateur de conteneurs et loadbalancer. 3) HAProxy : proxy TCP/HTTP et loadbalancer.
Notre détection s’exécute en deux étapes, la première consiste à détecter les images nginx, traefik ou bien haproxy dans le docker compose. Ensuite, l’outil va explorer les répertoires du projet pour localiser les fichiers de configurations. Chaque technologie a un fichier de format différent (nginx.conf, traefik.yml, haproxy.cfg), ensuite nous allons détecter la scalabilité des microservices. Chaque loadbalancer utilise une syntaxe pour répartir la charge entre les services dupliqués.
La sortie de l’outil sera sous 3 formes :
1) “Not present” qui signifie que le projet n’utilise pas de répartition de charge. 2) Si nous trouvons la technologie, mais les fichiers de configuration ne contiennent pas de la répartition entre les instances, on affiche la réponse “LoadBalancing and no Scalability”. 3) Le cas parfait, c’est lorsqu’on trouve les instances du services explicitées dans le fichier de configuration, on livre la réponse “LoadBalancing and Scalability”. Par conséquent, ond déduit que ce projet utilise très bien ce pattern de loadbalacing.
L’intégration/déploiement continue est parmis les principes qu’on doit trouver dans une architecture en microservices. En effet, la séparation du des fonctionnalités dans des services distribués nécessite une automatisation des tests, construction des images, déploiement, etc. Donc nous devons s’assurer que la CI/CD est appliquée sur chacun des microservices.
L’outil développé fera une première analyse pour vérifier si le projet possède déja une CI/CD, on procède en cherchant les technologies les plus communes comme (Jenkins, Travis CI et Circle CI). Ensuite, l’analyse va vérifier si les microservices sont présents dans les pipelines CI/CD. On suit la meme logique que nous avons abordé dans l’outil de déploiement individualisé, on va chercher les noms des repertoires des microservices dans les fichiers de CI/CD.
La sortie sera sous 3 formats :
1) “No CI/CD present “ si le projet ne possède pas de CI/CD. 2) “CI/CD present but no microservices found in it” si une CI/CD existe, mais les microservices ne sont pas présents dedans. Dans ce cas, la CI/CD sert à effectuer les builds, tests sur la globalité du projet. 3) Finalement, si les microservices sont présents dans la CI/CD, on affiche le résultat suivant : “microservices touched by CI/CD”
Le but des sorties non-binaires est de pouvoir juger l’utilisation du pattern dans l’architecture. Par exemple dans l’analyse CI/CD, si nous trouvons que le projet possède une chaîne CI/CD appliquée sur tous les microservices, cela confirme que ce concept est bien utilisé dans l’architecture. Par contre, avoir une CI/CD qui ne traverse pas chaque microservice n’est pas une bonne pratique, chaque microservice doit etre compilé, testé et déployé indépendamment. De même pour le Loadbalacing et les autres analyses qui ne retournent pas des sorties binaires, la sortie permet de donner une idée sur l’utilisation du pattern.
Nous sommes convaincus qu’il est envisageable d’analyser une architecture principalement à partir d’un fichier docker-compose. En examinant ce fichier de déploiement, nous avons identifié plusieurs informations et pistes d’exploration pour répondre à nos interrogations sur la validation d’une architecture microservice. La normalisation du fichier docker-compose.yml suggère des opportunités d’automatisation pour la détection de certaines composantes architecturales et de certains patterns.
Comme évoqué dans la partie III.2, des patterns tels que le CQRS demandent un investissement en temps considérable pour leur développement. Avec la contrainte temporelle qui nous a été imposée, il n’était pas envisageable de livrer des explorations approfondies dans des domaines tels que celui-ci, avec des outils capables de fournir des mesures suffisantes pour garantir leur reconnaissance de manière satisfaisante.
Nous partons donc du principe que, pour un projet donné ou une liste de projets spécifiques, nous serons en mesure d’évaluer certains principes d’une bonne architecture que nous aurons préalablement sélectionnés en amont, en injectant les liens GitHub correspondants dans notre application.
Nous croyons pouvoir simplifier l’aspect exploratoire et l’analyse des projets en centralisant l’analyse du docker-compose et en développant des outils qui ne seraient que des extensions spécialisées.
Pour expérimenter ces hypothèses, nous avons constitué un dataset de projets que nous avons préalablement étudiés. Ainsi, nous connaissons les résultats attendus pour ces projets. Lorsque nous soumettrons ce dataset à nos outils, nous pourrons valider ou invalider nos outils ainsi que nos hypothèses. Pour faire fonctionner nos outils, nous devons fournir un fichier CSV contenant les répertoires dans le format suivant (auteur/nom-du-repo). L’outil développé examinera les projets en analysant tous les principes mentionnés précédemment. En sortie, nous obtiendrons les résultats de chaque sous-analyse.
Avec un dataset préétabli et en connaissant les résultats attendus, nous soumettrons ces données à notre processus d’analyse pour valider non seulement notre travail, mais aussi nos hypothèses. Si les résultats de la grille de sortie correspondent à nos attentes basées sur nos observations des projets sélectionnés, nous serons en mesure de reconnaître une architecture en microservices selon nos critères.
Un rappel sur nos critères de validation : un bon projet microservice est un projet avec un fichier docker-compose, et le nombre de validations de certains principes dans la grille nous fournira un indice de confiance. Plus il y a de cases cochées dans la grille, plus le projet respecte les principes définis, et plus il sera considéré comme une bonne architecture microservice.
Pour des raisons de présentation, ce tableau ne correspond pas à celui généré par notre outil. En effet, la bibliothèque que nous utilisons ne permet pas de créer des tableaux visuellement élaborés. Les valeurs ne sont cependant pas modifiées.
Le tableau a été divisé en plusieurs lignes pour faciliter la lecture.
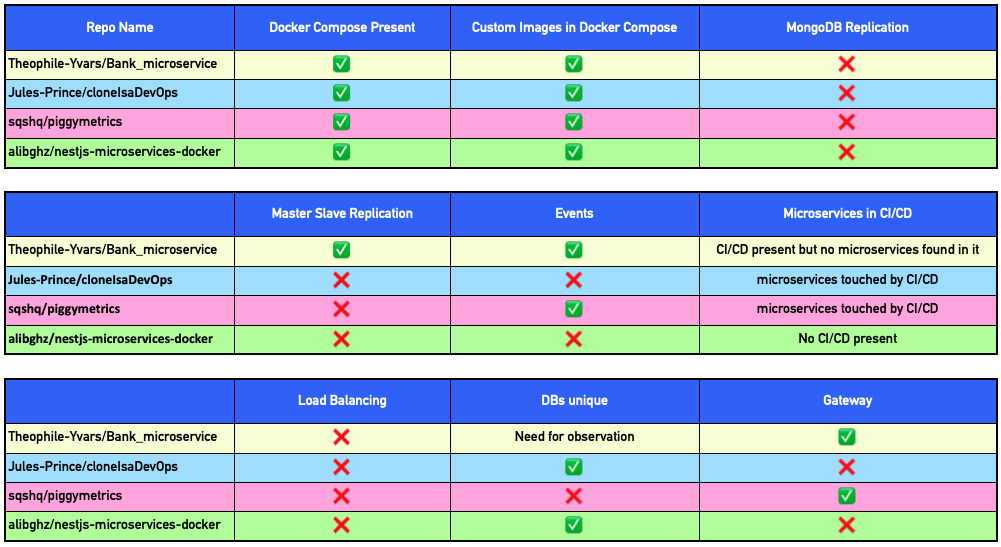
La grille obtenue nous permet d’identifier les forces et les faiblesses des architectures microservices sélectionnés en fonction de nos critères d’évaluation. Mais est-ce que ces résultats sont fiables ?
Puisque nous savons ce que nous attendons comme résultat, nous sommes en mesure d’évaluer les sorties de nos outils.
Tout d’abord, chacun de ces projets a un docker-compose qui a été correctement détecté. Nous n’avons pas mis de projet sans docker-compose, car cela a été testé en amont et nous n’avons pas jugé intéressant de montrer ce genre de résultat.
Dans la colonne Master - Slave du projet Theophile-Yvars/Bank_microservice, nous pouvons constater la présence de ce pattern. Lorsque nous observons dans le repo GitHub, dans le dockercompose, nous pouvons affirmer que ce résultat est celui que nous attendions.
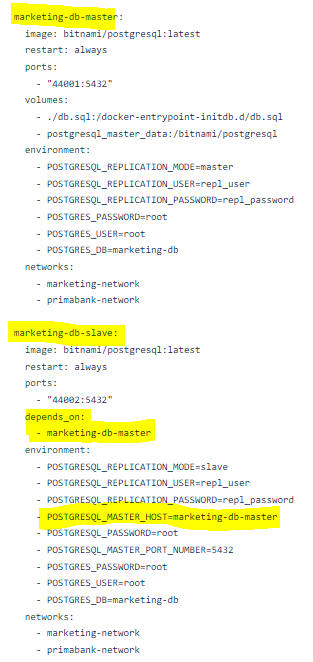
Figure : Pattern master-slave dans Theophile-Yvars/Bank_microservice
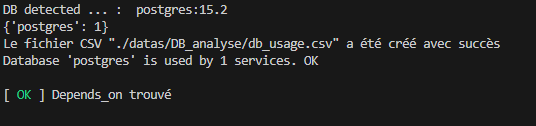
De plus, toujours pour le projet Theophile-Yvars/Bank_microservice, dans la colonne DBs unique, la grille nous informe de la nécessité d’observation.
L’outil qui est responsable de cette colonne nous donne plus d’information dans ces logs :

Figure : Nombre de dépendances des DBs
Comme le montre l’image ci-dessous, dans le cadre du projet, en raison du pattern master-slave et de l’architecture qui permet plusieurs implémentations possibles du service Marketing, la base de données est référencée à plusieurs reprises alors qu’elle est effectivement utilisée par un seul micro-service. Cet exemple met en lumière la complexité du résultat, qui ne peut être réduit à une dichotomie simple. Il devient impératif d’obtenir l’approbation de l’utilisateur lorsque la compréhension statique se révèle insuffisante.
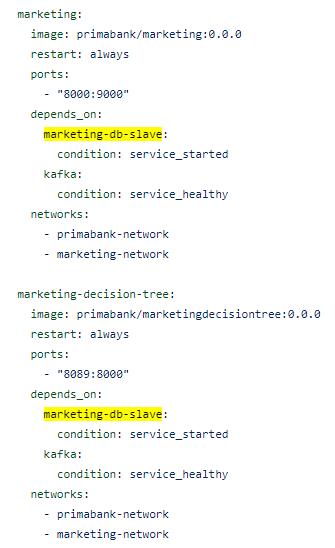
Figure : DB marketing-db-slave dans plusieurs depends-on
Ce répertoire est un bon candidat d’une architecture en microservices. Le projet contient une configuration docker-compose et chaque service est conteneurisé et déployé individuellement.
Il contient une CI/CD implémentée avec la technologie Travis CI. Tous les microservices sont présents dans la CI/CD. Le fichier .travis.yml peut confirmer cela : https://github.com/sqshq/piggymetrics/blob/master/.travis.yml
Il utilise le bus RabbitMQ pour l’envoi des événements entre les services. Finalement, nous constatons la présence d’une Gateway en Spring.
Selon notre outil, les microservices qui composent l’architecture sont les suivants :

En vérifiant dans le readme, nous trouvons bien que nous avons le meme nombre de microservices. Voici le lien de l’architecture du projet : https://cloud.githubusercontent.com/assets/6069066/13906840/365c0d94-eefa-11e5-90ad-9d74804ca412.png (en comptant le Gateway comme microservice).
Comme nous constatons dans la grille, ce projet contient 5 patterns parmi les 9 que nous avons discutés auparavant, ce qui signifie la cohérence entre notre outil et l’analyse manuelle du répertoire.
Ce projet a été développé pas une équipe en 4ème année en cycle d’ingénieur à Polytech Nice Sophia. Ce projet consistait à développer une application de cartes de fidélité sous forme d’un monolithe. Donc ce projet est un mauvais candidat d’architecture en microservices.
Le projet est composé d’un backend qui contient toute la logique métier de la banque, et des systèmes externes pour modéliser d’autre fonctionnalités externes (parking et banque). Il possède également une CI/CD avec l’outil Jenkins. Le but de cette expérimentation est pour montrer les limites de notre outil dans la détection des faux positifs. Mais qu’est ce qu’on veut dire avec un faux positif ?
Dans ce contexte un faux positif est une architecture non-microservices, mais qui contient les patterns mentionnés avant et qui sera notée positivement par notre outil.
En analysant le résultat, nous remarquons que le projet contient un docker compose avec des déploiements individualisés. Cependant, en analysant manuellement le fichier, le docker-compose nous constatons que les déploiements individualisés sont pour le backend et les systèmes externes. Donc notre outil les a considérés comme des microservices/services. De plus, l’analyse de la CI/CD nous donne la réponse “Microservices touched by CI/CD”, l’interprétation de ce résultat est la même que l’analyse du déploiement individualisé. La CI/CD portait sur le monolithe et les systèmes externes.
Et pour les bases de données, nous avons comme résultat que la base de données postgres est utilisées par un seul microservice. C’est normal puisqu’il s’agit d’un seul monolithe qui écrit/lit dans une base de données unique.
Cette expérience permet de justifier la validation d’un faux positif par nos outils, cela revient aux ressemblances d’implémentations des patterns entres les architectures en microservices et en monolithe. En effet, les fichiers docker compose et ceux de la CI/CD ont une implémentation identique pour tous les types d’architectures.
Par conséquent, nous avons décidé d’implémenter un outil auxiliaire qui va permettre de détecter si l’architecture est potentiellement en microservices afin de valider ou pas les résultats de l’analyse.
Cet outil fonctionne en cherchant les mots-clés en relation avec les microservices pour faire une validation du projet. De plus, il permet de calculer la taille des différents répertoires du projet, en donnant comme sortie le plus grand répertoire et la moyenne des tailles des répertoires. Normalement, si une bonne architecture doit contenir des microservices avec plus ou moins la même taille. L’essentiel, c’est qu’on trouve pas un gros microservice parce que c’est un indice qu’il a beaucoup de responsabilités.
En lançant cette dernière analyse sur la même liste des projets nous avons les résultats suivants :

Premièrement, la première colonne est le résultat de la recherche des mots-clés (microservice, service-oriented, …) dans les readme, les fichiers et les descriptions. Nous constatons que pour le faux positif que nous avons traité avant “Jules-Prince/cloneIsaDevOps” le résultat est “FAUX”, donc l’outil n’arrive pas à trouver une référence aux microservices dans les descriptions. D’autre part, l’outil a validé les résultats pour les autres répertoires.
Pour le projet sqshq/piggymetrics, nous constatons que le service “notification-service” est le plus grand avec 3622 bytes et la moyenne de taille de tous les fichiers est 2101. Donc tous les services ont plus ou moins la même taille, cela valide le résultat de l’analyse précédente. Pour les projets alibghz/nestjs-microservices-docker et alibghz/nestjs-microservices-docker, nous remarquons que la taille du plus grand microservice n’est pas loin de la moyenne. Donc, nous pouvons supposer que les responsabilités sont bien réparties entre les services.
Nous sommes conscients que la validation avec les tailles des répertoires est un peu limitée, c’est parce que le projet peut contenir des répertoires de configuration, des front-end qui sont généralement grands en termes de taille.
La présence des mots-clés dans les descriptions permet d’approuver l’architecture en microservice du projet, l’absence de ces mots-clés va donner un indice à l’utilisateur pour faire une validation manuelle du projet.
La première limite que nous nous sommes imposée est de ne traiter que les projets utilisant un fichier docker-compose. Nous pourrions étendre notre analyse aux environnements sur Kubernetes en examinant des fichiers de déploiement tels qu’Ansible ou Terraform. Nous pourrions également analyser des projets non conteneurisés.
Ensuite, nous ne sommes pas en mesure de détecter correctement si un service est un microservice. Nous pourrions évaluer cela en tentant d’analyser si le service possède uniquement un agrégat. De même que pour l’analyse des services et de leurs dépendances aux bases de données, nous pourrions compter le nombre d’agrégats par service. Si un service a plus d’un agrégat, cela indiquerait qu’une vérification manuelle de l’architecture est nécessaire.
Puisque nous ne sommes pas en mesure de détecter correctement si un service est un microservice, nous pouvons obtenir des résultats avec plusieurs cases valides dans notre grille, alors qu’il s’agit d’un monolithe. On peut avoir une stack Docker avec quelques microservices gravitant autour d’un gros monolithe et avoir une grille qui nous informe que l’architecture est satisfaisante. Ainsi, des faux positifs pourraient se produire dans ce cas.
Nous avons limité le nombre d’outils à ce qui était réalisable dans le temps imparti, en veillant à avoir suffisamment d’outils pour obtenir une vue globale de l’architecture et pouvoir approfondir l’analyse de ces outils afin d’obtenir une interprétation fiable pour le plus grand nombre de cas possible.
1. Extension des Outils d’Analyse : Étant donné que nous avons limité le nombre d’outils en raison de contraintes de temps, une amélioration future pourrait consister à étendre la gamme d’outils d’analyse. Par exemple, l’ajout d’outils spécifiques pour détecter le pattern CQRS (Command and Query Responsibility Segregation) ou d’autres patterns couramment utilisés dans les architectures en microservices.
2. Détection Automatique des Microservices : Actuellement, notre approche se base sur l’analyse statique des fichiers de configuration. Une amélioration majeure serait de développer des techniques de détection automatique des microservices, peut-être en utilisant des méthodes d’analyse dynamique ou des techniques d’apprentissage automatique pour identifier les frontières des microservices dans le code.
3. Gestion des Faux Positifs : L’amélioration de la gestion des faux positifs est un domaine clé. Développer des mécanismes plus sophistiqués pour distinguer les projets qui utilisent des technologies similaires, mais ne suivent pas nécessairement une architecture en microservices, serait bénéfique.
4. Intégration avec d’Autres Plateformes : Actuellement, nos outils se concentrent principalement sur les projets GitHub et utilisent l’API GitHub. Une extension possible serait de permettre l’analyse de projets provenant d’autres plateformes telles que GitLab, Bitbucket, ou d’autres dépôts Git autonomes.
1. Intégration de Scénarios Réels : Pour améliorer la validité de nos résultats, une prochaine étape consisterait à intégrer des scénarios réels issus d’entreprises utilisant des architectures en microservices. Cela pourrait fournir une base plus solide pour tester nos outils et garantir leur pertinence dans des situations du monde réel.
2. Collaboration avec la Communauté : En ouvrant nos outils à la collaboration avec la communauté, nous pourrions bénéficier des commentaires, des contributions et des ajustements suggérés par d’autres experts en architecture en microservices. Cela pourrait conduire à une amélioration continue et à une adaptation des outils aux besoins diversifiés de la communauté.
3. Raffinement des Critères d’Évaluation : Les critères utilisés pour évaluer une architecture en microservices peuvent être continuellement raffinés. Travailler en étroite collaboration avec des experts en architecture logicielle pour affiner ces critères et les adapter aux évolutions technologiques permettrait de garantir la pertinence continue de nos analyses.
4. Intégration d’Outils d’Analyse Dynamique : En plus de l’analyse statique, l’intégration d’outils d’analyse dynamique pourrait offrir une vision plus complète des performances et de l’efficacité des architectures en microservices. Cela pourrait inclure des métriques de performance, de disponibilité et de scalabilité des microservices.
5. Documentation Approfondie : Fournir une documentation approfondie sur l’utilisation de nos outils, y compris des guides pas à pas et des exemples d’application, pourrait rendre l’ensemble du processus plus accessible aux utilisateurs et aux développeurs intéressés par l’analyse des architectures en microservices.
En conclusion, notre exploration approfondie des architectures en microservices à travers l’analyse statique des fichiers Docker Compose et d’autres éléments clés des projets a permis de formuler des hypothèses, de concevoir des outils d’analyse et d’expérimenter leur validité sur un ensemble diversifié de projets.
L’évaluation de ces outils sur des cas d’utilisation réels a révélé des forces et des limites dans notre approche. La grille de résultats obtenue a fourni des indications précieuses sur la conformité des architectures aux critères définis, tout en soulignant la nécessité d’une validation manuelle et d’une gestion plus fine des faux positifs.
Les améliorations et perspectives identifiées indiquent un chemin vers une évolution continue de nos outils, en mettant l’accent sur la détection automatique des microservices, la gestion des faux positifs, l’extension des critères d’évaluation et l’intégration avec d’autres plateformes. En outre, l’ouverture à la collaboration avec la communauté et l’intégration d’outils d’analyse dynamique sont des éléments clés pour renforcer la pertinence et l’applicabilité de notre approche.
Notre projet a ainsi jeté les bases d’une analyse automatisée des architectures en microservices, offrant une contribution significative à la compréhension et à l’évaluation de ces architectures complexes. Tout en reconnaissant les défis et les limites, notre travail ouvre la voie à des développements futurs visant à rendre ces outils plus robustes, adaptatifs et largement applicables dans des scénarios réels d’ingénierie logicielle.
| Qu’est-ce que l’architecture de microservices ? | Google Cloud | Google Cloud. (s. d.). Google Cloud. https://cloud.google.com/learn/what-is-microservices-architecture?hl=fr#:~:text=Dans%20une%20architecture%20de%20microservices,r%C3%A9pondre%20%C3%A0%20des%20probl%C3%A9matiques%20m%C3%A9tier |
Les microservices, qu’est-ce que c’est ? (s. d.). https://www.redhat.com/fr/topics/microservices/what-are-microservices
Contributeurs aux projets Wikimedia. (2023, 17 mai). Microservices. https://fr.wikipedia.org/wiki/Microservices
| Que sont les microservices ? | AWS. (s. d.). Amazon Web Services, Inc. https://aws.amazon.com/fr/microservices/ |
| Que sont les microservices ? | IBM. (s. d.). https://www.ibm.com/fr-fr/topics/microservices |
| Kassel, R. (2023, 9 novembre). Microservices : définition, fonctionnement, avantages. Formation Data Science | DataScientest.com. https://datascientest.com/microservices-tout-savoir |
Martinekuan. (s. d.). Style d’architecture orientée microservices - Azure Architecture Center. Microsoft Learn. https://learn.microsoft.com/fr-fr/azure/architecture/guide/architecture-styles/microservices
Que sont les microservices ? définition et architecture. (s. d.). MuleSoft. https://www.mulesoft.com/fr/resources/api/what-are-microservices
En savoir plus sur l’architecture des applications basées sur les microservices sur Oracle Cloud. (s. d.). Oracle Help Center. https://docs.oracle.com/fr/solutions/learn-architect-microservice/index.html#GUID-BDCEFE30-C883-45D5-B2E6-325C241388A5