Nous sommes quatre étudiants en dernière année à Polytech Nice Sophia :
Nous avons choisi de restreindre le sujet en parlant de localisation (l10n) et non pas d’internationalisation (i18n). En effet la i18n permet de concevoir et développer une application qui permet de facilement mettre en place la l10n.
La localisation est le fait d’adapter un logiciel à un marché international. Cela inclut la traduction bien sûr, mais aussi le fait d’adapter l’interface et les tests afin d’être sûrs que le programme fonctionnera dans le langage visé.
En choisissant l10n cela nous permet de réduire l’amplitude du sujet et donc d’avoir une question plus spécifique.
Nous avons choisi de restreindre le sujet en parlant de localisation (l10n) et non pas d’internationalisation (i18n). En effet i18n permet de concevoir et développer une application qui permet de facilement mettre en place l10n. En choisissant l10n cela nous permet de réduire l’amplitude du sujet et donc d’avoir une question plus spécifique. Nous avons choisi de poser la question : “Quel est l’impact des techniques de mise en oeuvre de la localisation sur les projets informatique ?”. Nous avons défini les techniques comme un ensemble des framework, librairies ou développement dédiés à gérer de multiples langues dans un projet. Cette question est intéressante puisqu’elle touche à deux aspects, quelles techniques sont utilisées, mais aussi est-ce que ces techniques apportent des contraintes sur le projet , et lesquelles sont-elles ?
Dans le cadre de nos questions nous cherchons principalement à conduire des recherches empiriques sur des projets existants. Nous allons donc chercher à explorer des projets existants qui mettent en place de la l10n et extraire de ces derniers des données pertinentes pour nos questionnements.
Pour ce faire, nous nous appuierons sur des sites regroupant des projets qui ont intégrés de la l10n, et l’accès à leur code source, comme Weblate qui permet sur sa plateforme principale la traduction participative ouverte au public.
Egalement afin d’élargir le champ de recherche nous conduirons une recherche sur Github parmi les projets java les plus populaires, afin d’estimer comment est appliquée la l10n et obtenir un autre échantillon de statistiques indépendantes de l’outil Weblate.
La sélection se fera à travers du webscrapping et des requêtes aux API des différents sites, afin d’extraire des projets en java et les liens de leur repository sources. Une fois les différents projets sélectionnés, nous appliquerons des scripts d’analyse détaillés en IV, implémentés en python.
Pour cette expérience, nous avons d’abord récupéré des projets java depuis la source Weblate avec un script python [script.1]. Puis nous avons effectué des analyses sur ces projets. Tous les outils utilisés pour effectuer les analyses sont des scripts python que nous avons développés.
Nous avons choisi d’effectuer deux types d’analyses.
La première concernant la structure d’un projet :
Lors de la première itération, nous avons remarqué qu’une majorité des projets weblate java étaient en fait des projets Android. Les projets Android ont une gestion de la traduction particulière qui demande d’adapter notre première étape. Même si les fichiers sont différents, le but reste le même pour chaque étape déterminer l’influence sur l’architecture et le nombre de fichiers Java impactés.
La deuxième analyse concerne la gestion de version avec :
Déterminer le nombre de fichiers impactés lors des commits liés à la localisation. Cette analyse permettra de savoir combien de commits sont liés à la localisation, et de voir quelle proportion prend la localisation sur le développement d’une application [script.6]
Parcourir les branches pour déterminer si une branche est spécifique à la traduction [script.7]. Ces résultats montreront si une branche est spécifique à la gestion d’l10n ou non.
Toutes ces informations nous permettront d’avoir des métriques simples pour répondre à notre question “Quel est l’impact des techniques de mise en œuvre de la localisation sur les projets informatiques”.
Afin d’avoir une donnée globale nous avons analysé les 1000 projets Java les mieux notés sur Github pour avoir une estimation du nombre de projets faisant de la traduction (tous outils confondus).
Concernant l’organisation, nous avons procédé en deux étapes pour chaque analyse. Tout d’abord créer un script permettant de récolter une information spécifique puis créer un ou plusieurs graphiques depuis ces résultats afin de mieux les visualiser et les analyser. Chaque membre de l’équipe a créé des scripts et des graphiques.
Projets Android : Concernant l’architecture des projets elle n’est pas impactée par la gestion de la localisation puisque tous les projets androids suivent la même norme qui consiste à ranger les fichiers de traduction dans le répertoire “res” à la racine. La gestion des différentes langues se fait avec différents répertoires “values”. Un répertoire va correspondre à une langue par exemple /res/values-de contenant un fichier “strings.xml”.
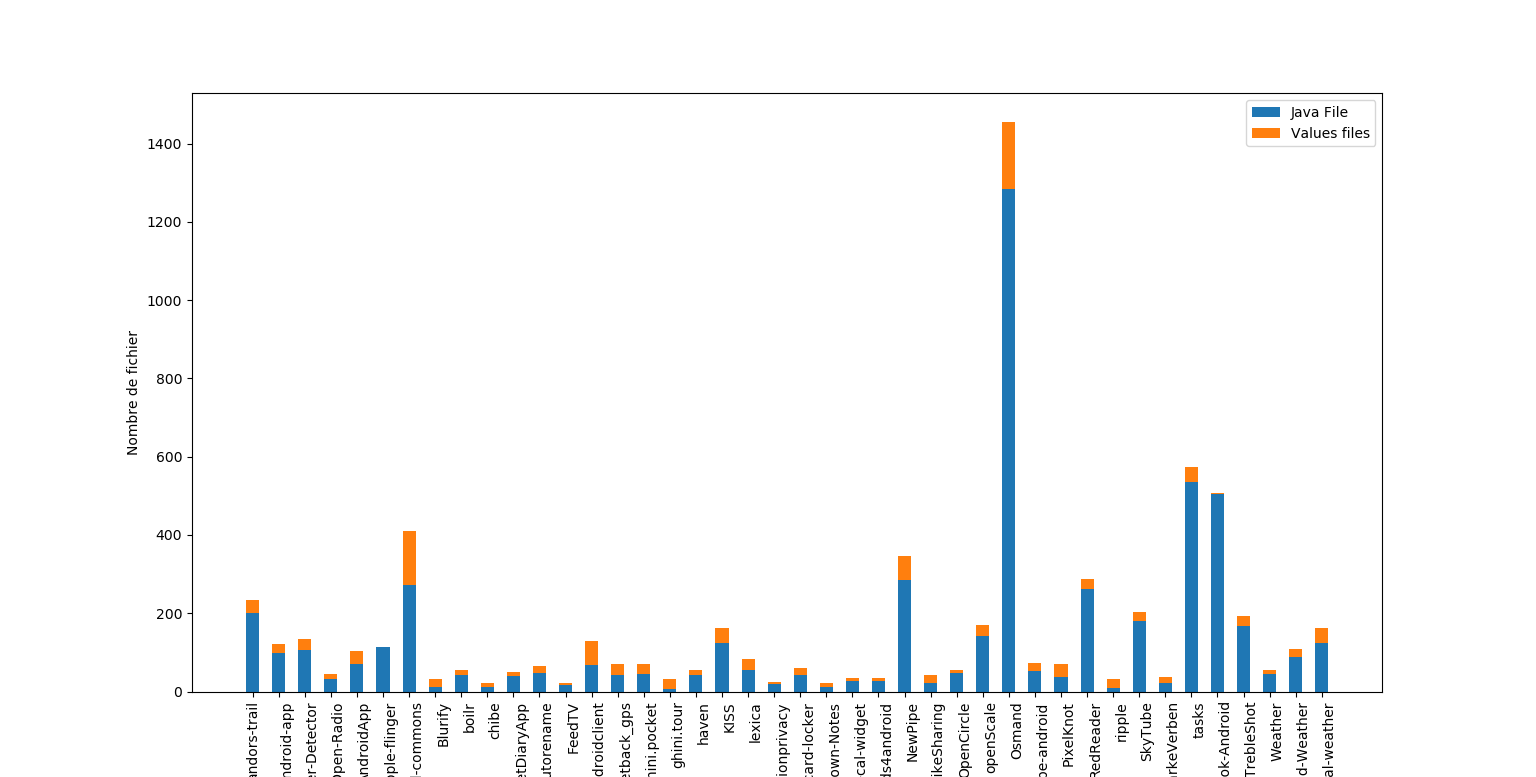
Nous pouvons voir grace au graphique ci-dessus que la taille des projets (ici le nombre de java file sert de références) n’a pas d’incidence sur la quantité de langue traduite. On peut aussi remarquer que les projets qui sont plus petits ont une grosse quantité de langues traduites (par exemple: mini.pocket, PixelKnot, card-locker) par rapport à leur quantité de fichiers java.
Projets Java : Concernant les projets Java nous pouvons constater que la localisation des fichiers liés à la l10n est dispatchée dans différents répertoires. Pour certains projets tel que “Jenkins” et “che”, les properties sont séparées dans plus de 250 répertoires. Pour la majorité des projets analysés, ces fichiers sont distribués dans moins de 50 répertoires.
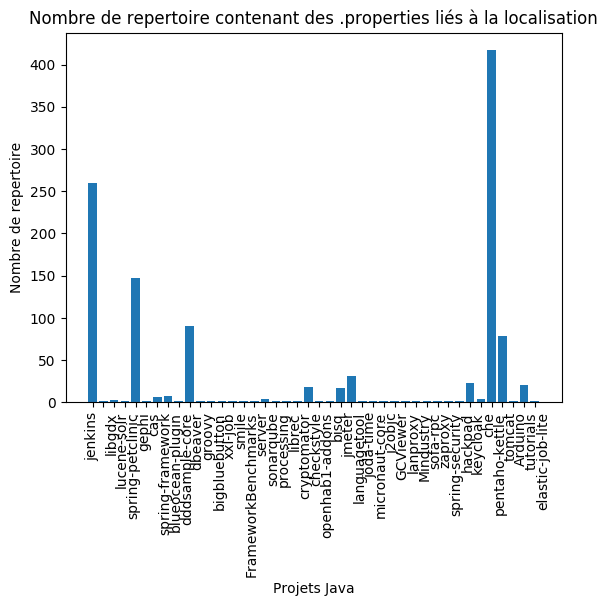
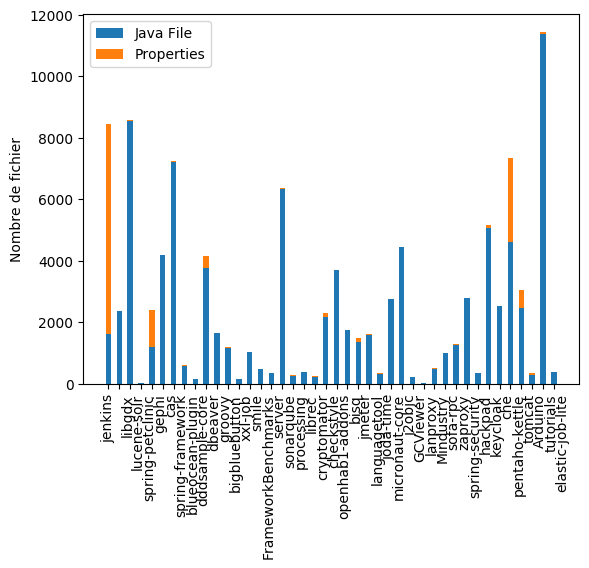
Si nous comparons ces résultats avec la proportion de fichiers properties et fichiers java, nous constatons une corrélation entre les deux. Effectivement, les projets ayant peu de fichiers properties correspondant à la traduction sont ceux qui ont le moins de répertoire les contenant. Si nous reprenons l’exemple de “Jenkins”, on voit qu’il y a plus de fichiers properties de traduction que de fichier java et que cela a un impact sur l’architecture du projet, puisque ces fichiers properties sont contenus dans plus de 250 répertoires. De même pour le projet “che”, même si la quantité de traduction est moins élevée que pour “Jenkins”, cela semble toujours avoir un impact sur l’architecture, puisque les fichiers liés à localisation sont contenus dans plus de 400 répertoires. Cette corrélation est aussi visible pour les projets “spring-petclinic”, “ddsample-core” et “pentaho-kettle”.
La structure des projets android ne semble pas impactée par la localisation. Cela peut s’expliquer par la norme de placement des fichiers de traduction dans le répertoire “res”. En revanche, les projets Java purs semblent impactés, cela peut s’expliquer par le manque de norme. Chaque projet semble gérer ses emplacements différemment, et aucun projet ne place tous ses fichiers de traduction au même endroit, ce qui impacte la structure globale.
Commits de localisation :
Lorsqu’on étudie le graphique représentant le pourcentage de commits liés à la localisation sur la branche master, on se rend rapidemment compte que le pourcentage est extrêment variable.
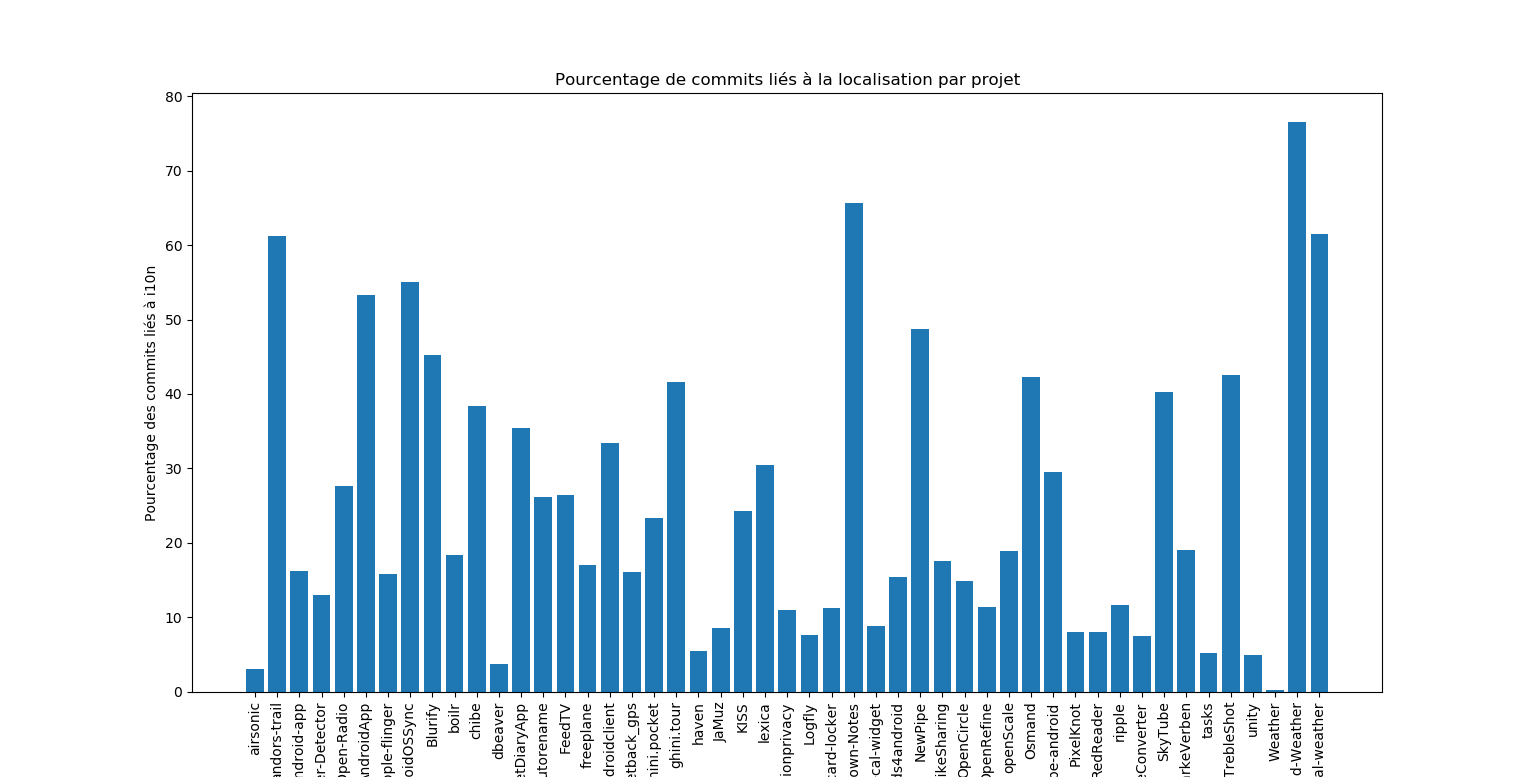 Si on omet les projets n’ayant aucun commit de localisation, le plus bas est à 1%, et le plus haut est à 76%.
Cette disparité dans le pourcentage nous a étonné, car nous nous attendions à ce que l’automatisation avec weblate permette de garder le nombre de commits assez bas, et régulier entre différents projets.
Si on omet les projets n’ayant aucun commit de localisation, le plus bas est à 1%, et le plus haut est à 76%.
Cette disparité dans le pourcentage nous a étonné, car nous nous attendions à ce que l’automatisation avec weblate permette de garder le nombre de commits assez bas, et régulier entre différents projets.
La question s’est ensuite posée de savoir si une branche en particulier était dédiée à la localisation. Pour cela nous avons réalisé un graphique en batons avec 3 valeurs pour chaque projet :
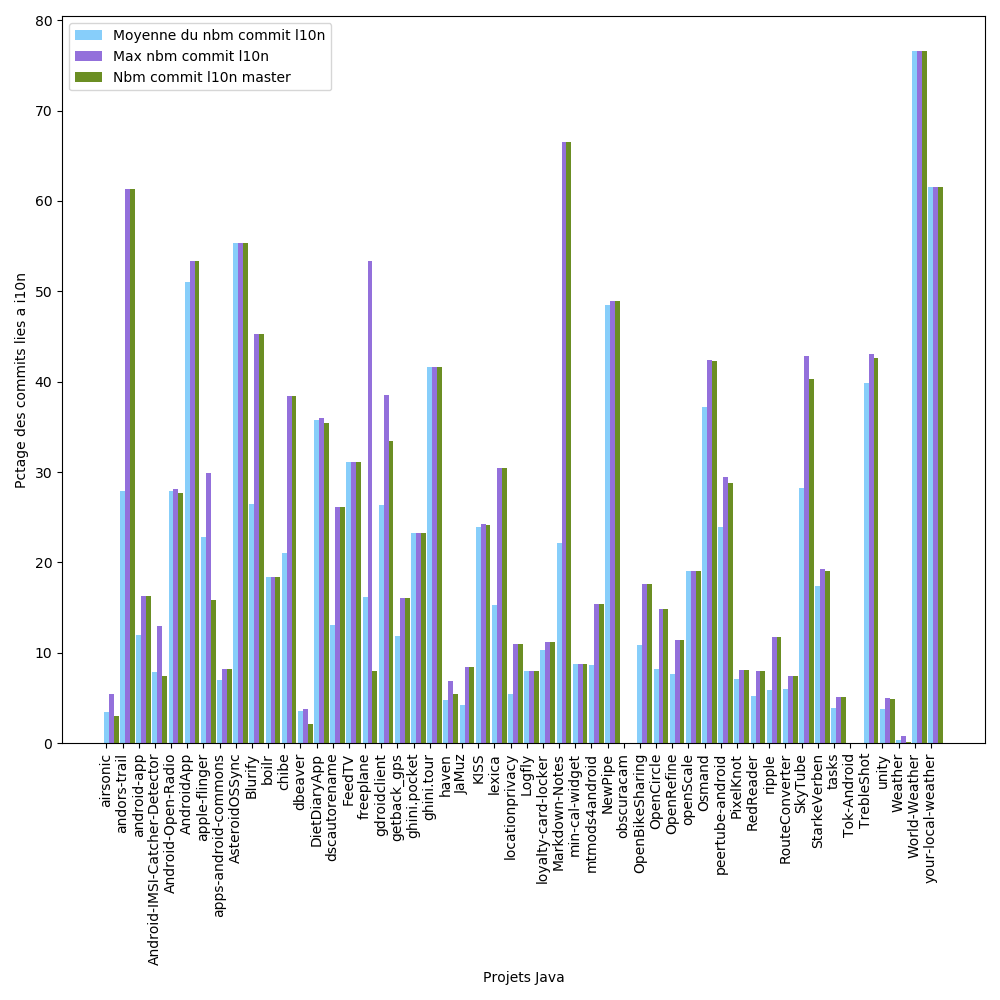
Globalement, on observe qu’il n’y a pas de branches dédiée à la localisation, car seuls 2 projets montrent une différence notable entre le pourcentage maximal et le pourcentage moyen. On remarque aussi qu’un bon nombre de projets (33 / 64) ont leur pourcentage de commits sur master égal au pourcentage maximal de commits, on peut donc supposer que master est la branche dédiée à la localisation pour ces projets là.
Encore une fois, nous nous n’attendions pas à ce résulat, et nous pensions voir beaucoup plus de projets possédant une branche de localisation dédiée autre que master.
On peut toutefois remarquer que le pourcentage de commits de localisation en moyenne sur toutes les branches reste globalement assez proche du nombre de commits maximal, ce qui peut montrer qu’il n’y a pas de grande disparité entre la répartition des commits sur les branches. Avec ces valeurs, si on observe que la branche maximale a la même valeur que master, c’est que la localisation se concentre majoritairement sur master.
Nous avons également souhaité étudier la répartition des commits en fonction des auteurs : si le commit a été fait par un humain ou par Weblate. Nous avons donc réalisé un diagramme en boite à moustaches du pourcentage de répartion de commits de localisation réalisé par Weblate sur tous les projets.
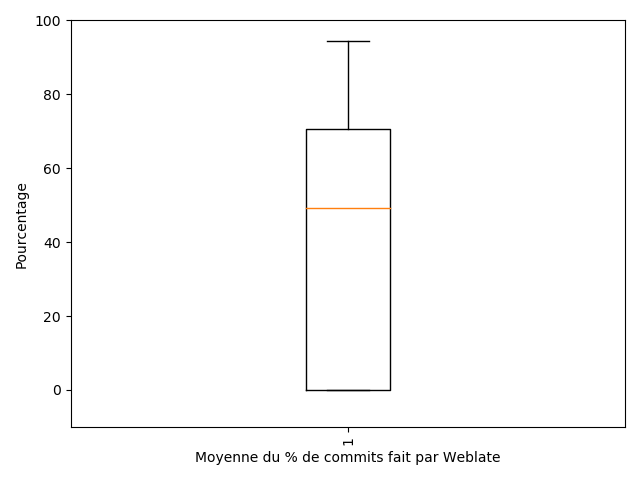
La moyenne est à 50%, le minimum est à 0% et le maximum à 95%. Cela représente donc un grand écart type.
Nous sommes encore une fois surpris d’avoir la moitié des commits de localisation réalisés par des humains, car nous attendions à un pourcentage assez faible, compte tenu de l’automatisation des commits par Weblate.
Enfin nous avons souhaité analyser la répartition des commits dans le temps. Pour cela nous avons compté le nombre de commits lié a la localisation à chaque date de chaque projet, et fait en sorte de normaliser les comptes sur une échelle de 0 à 100, à 0 étant le premier commits detecté, à 100 le dernier detecté. Cela nous donne le graphique suivant.
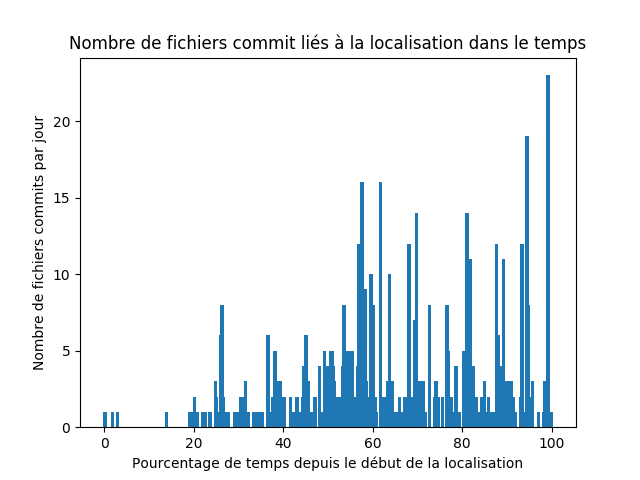
On voit donc une répartition relativement disparate après une période de plateau où les projets ne versionnent pas de travail liés a la localisation. Et on observe la même chose sur les projets selectionnés à travers weblate où les projets appliquant la l10n parmi les 1000 plus populaires sur github représentés ci dessous:
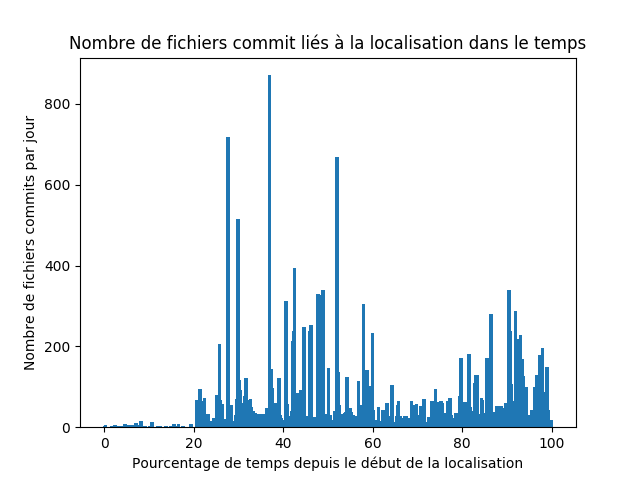
Afin de chercher a exclure les phénomènes ponctuels de commits massifs qui pourraient être effectués sur certains projets
nous avons réalisé un graph la moyenne du nombre de fichiers versionnés par pourcentage de temps écoulé, à nouveau pour les deux ensembles de projets.

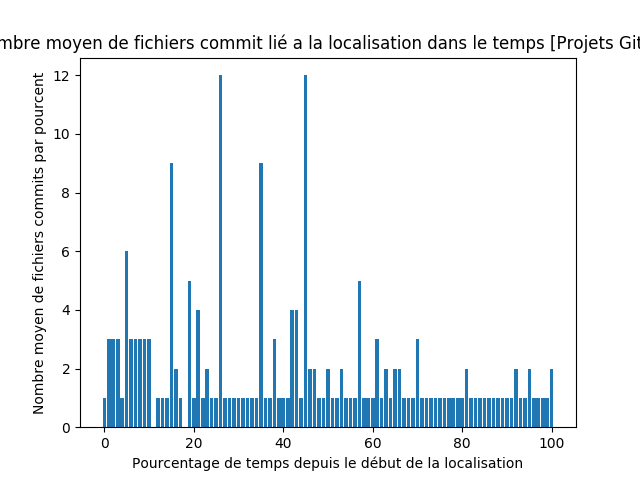
Nous voyons alors un nombre de commits beaucoup plus homogène au cours du temps, à nouveau quelque soit l’échantillon de projets.
Nous pouvons donc voir que les projets tendent en moyenne à avoir une activité constante, cependant parsemée de grand nombre de fichiers commités d’un coup.
Après avoir vu l’analyse des commits liés à la localisation, nous allons regarder les résultats de l’analyse dans le code pour voir les marqueurs qui font référence aux clés présentes dans des fichiers properties pour récuperer la valeur associée à cette clé.
Voici ci-dessous les résultats obtenus séparés en deux parties, les projets Android et les projets Java/JSP car les façons de rechercher les marqueurs étaient radicalement différentes.
{
"Android stat": {
"average": 14.591324874594275,
"averageOccurrencePerProject": 109.54545454545455,
"totalNbFile": 6778,
"totalNbFileWithKey": 989,
"totalNbOccurrence": 4820
},
"Java stat": {
"average": 9.652063345278004,
"averageOccurrencePerProject": 921.5,
"totalNbFile": 8651,
"totalNbFileWithKey": 835,
"totalNbOccurrence": 3686
}
}
On peut observer tout d’abord que la présence des marqueurs de traduction est plus forte en moyenne dans les fichiers des projets Android que dans les fichiers Java, même si globalement, les projets Java ont plus de fichiers Java/JSP que les projets Android. Les projets Androids ont aussi plus de marqueurs que les projets Java; cela peut s’expliquer par la facilité d’implementation de la localisation qui est supportée par le framework Android. Mais on voit par contre, dans les projets Java, qu’il y a, en moyenne, dans les fichiers, plus de marqueurs.
Donc dans le cas d’un changement de clé dans les fichiers properties, il va y avoir plus de fichiers à modifier dans les projets Android, mais moins d’appels de marqueurs par fichier que dans les projets Java.
Par contre, on remarque une grosse différence pour le nombre moyen d’occurences de marqueurs par projets, et les projets Java ont en moyenne 900 occurences contrairement au projets Android qui en ont 100.
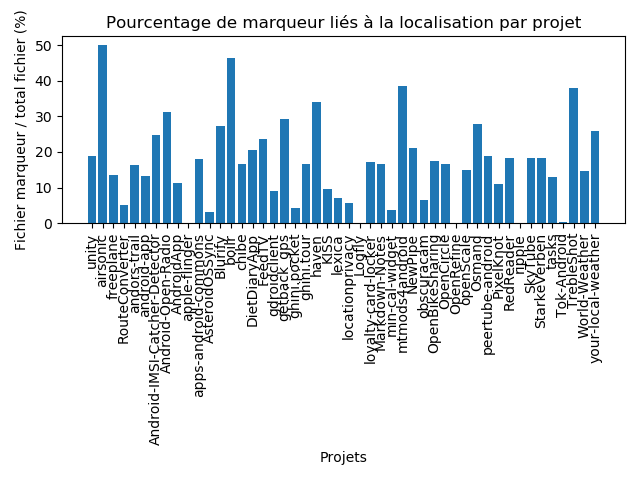
Sur ce graphique, on peut distinguer que certains projets ont jusqu’à 50% de fichiers avec des marqueurs et certains projets en ont environ 0%.
Pour résumer les résultats sur l’analyse des marqueurs, on observe que dans les projets Android et Java, l’impact qu’apporte un changement sur les clés de traductions a modifié en moyenne 14.5% des fichiers dans les projets Android contre 9.5% dans les projets Java. Mais quand on regarde cas par cas, le total de fichiers avec des marqueurs est extrêment variable, et ces observations sont donc à nuancer.
Rappelons les questions posées au début :
On est capable d’identifier l’impact de la localisation, et plusieurs types d’impacts :
Au niveau de l’impact sur la structure, l’architecture des projets android ne semble pas impactée par la localisation. Cela peut s’expliquer par la norme de placement des fichiers de traduction dans le répertoire values. En revanche les projets Java purs semblent impactés. Cela peut s’expliquer par le manque de norme, qui entraîne donc pour chaque projet une gestion différente, donc un impact différent sur chaque structure de projet.
Si on étudie la localisation au niveau du fichier, on peut remarquer que les marqueurs de traduction se trouvaient dans beaucoup de fichiers différents (encore plus fort dans les projets android). De même que pour la structure des projets, comme il n’existe pas de norme en Java, chaque projet gère à sa façon les marqueurs de traduction.
Pour résumer cette réponse, en ce qui concerne la structure de projet l’impact est très fort sur les projets Java et plus faible sur les projets Android. Pour les fichiers de code, l’impact est nuancé, 9% des fichiers concernés en moyenne, avec toutefois un très fort écart type : de 0% à 50% Enfin, pour l’impact dans le temps, les conséquences de la l10n sont globalement faibles (en moyenne 2 fichiers par unité de temps relative à la durée de vie du projet) mais elles sont constantes tout au long du projet.
Lorsque qu’on étudie la corrélation entre la gestion de version et l’impact de la l10n, on se rend compte que l’impact est très variable selon les projets. Certains projets n’ont que 1% de leur commits liés à la l10n, alors que d’autres en ont 76%. Cela peut sans doute s’expliquer par la disparité de structure entre les projets.
Au niveau de la gestion des branches, on ne distingue pas de forte tendance à avoir une branche dédiée à la 10n autre que master. Cette tendance peut s’expliquer par le fait que les branches seront éventuellement mergées sur master.
Enfin, au niveau de la répartition des auteurs, nous avons un pourcentage de 50% de commits automatiques par Weblate et de 50% de commits fait par des humains. Il est pour l’instant dur pour nous de définir si cela est un résultat significatif et si on le retrouverait avec un autre outil que Weblate, mais il serait intéressant d’étudier cela.
Les principales menaces à la validité des résultats se situent dans nos hypothèses et nos échantillons de départ. En effet, récupérer des projets open source sur Weblate peut provoquer un biais dans les résultats, car les projets open source ne fonctionnent pas de la même manière que des projets “privés”.
De plus, pour déterminer les commits liés à la localisation nous utilisons des mots-clés [“localization”, “l10n”, “i18n”, “internationalization”, “translate”, “translation”, “weblate”] Ces derniers peuvent couvrir des commits qui ne concernent pas la l10n (ex : API Translation from SOAP to REST), ou en exclure d’autres (ex : Fix french) Pour essayer de corriger ce problème, nous avons déterminé un indice de confiance. Nous avons choisi 170 commits identifiés comme commits de localisation et nous avons vérifié qu’il s’agissait bien de cela. Nous avons donc obtenu que 90% de ces commits étaient effectivement des commits de traduction. C’est un indice de confiance élevé, nous avons donc assez confiance en ces résultats.
###Outils