Nous sommes quatre étudiants en 5ème année de diplôme d’ingénieur à Polytech Nice-Sophia, spécialisés en architecture logicielle :
De plus en plus de systèmes actuels utilisent des logiciels conteneurisés. Or, il existe de nombreux moyens de paramétriser des conteneurs Docker, et cela crée une forte hétérogénéité entre les différents projets.
Ces nombreux moyens possibles de paramètrisation permettent de faire varier le comportement au cours des différents cycles de vie d’une application. Dans le cadre de notre recherche, nous avons décidé de nous concentrer sur les phases suivantes :
Si nous avons choisi ces trois phases c’est parce qu’elles représentent les principaux moments où l’application est impactée par les paramètres de haut niveau.
Nous avons décidé d’exclure les projets utilisant un docker-compose et donc plus généralement les solutions utilisant une architecture micro-service. Ceux-ci sont trop spécifiques à analyser car ils contiennent énormément de duplication d’information entre les mico-services, contrairement aux projets monolythes qui n’utilisent qu’un seul Dockerfile pour s’exécuter dans un environement donné. Si nous avions pris en compte les projets micro-services, cela aurai rendu nos résultats incohérents. Cependant, il serait intéressant pour une future étude de les intégrer, mais en considérant que chaque service est un projet à part entière.

Quels sont les paramètres utilisés dans les différents cycles de vie d’une application conténeurisées ? Y a-t-il des similarités entre differents langages de programmation ?
L’intérêt principal de ces questions est de pouvoir déterminer s’il existe des normes pour un langage donné. De plus, nous voulons savoir si celles-ci sont généralisables à un ensemble de projets informatiques ou si les différentes technologies ont un impact sur la manière de paramétriser une application.
L’objectif, s’il existe des normes ou généralités de paramétrisation, serait de faciliter la construction d’une solution conteneurisé en établissant des templates d’utilisation de docker ou encore en automatisant un maximun d’actions récurrentes.
Le premier travail de notre recherche a été de définir des catégories de types de paramètre de haut niveau à partir d’une analyse statique et manuelle d’un petit ensemble de projets.
Cela nous a permis par la suite de développer des algorithmes capables d’analyser en grand nombre de projets en labélisant les paramètres trouvés dans les catégories suivante :
Dans le cadre de nos recherches nous avons décidé de nous concentrer dans un premier temps sur les projets développés en GoLang car ceux-ci ont des particularités très intéressantes :
Ensuite nous avons décidé d’effectuer une comparaison avec des projets en Java car c’est un langage qui est beaucoup utilisé dans l’industrie.
Pour nous guider dans nos recherches nous avons émis les hypothèses suivantes :
Pour essayer de confirmer ou invalider nos hypothèses nous avons généré toutes sortes de graphes afin d’avoir une visualisation des données récupérées sur notre ensemble de projets.
Nous avons généré des graphes pour chaque cycle de vie d’une application: build (construction application/compilation du code source), exec (construction de l’image docker) et run (instanciation de l’image docker en un conteneur). Ceux-ci mettent en avant le taux d’apparition des exposes, args, volumes, nombre de variables d’environnement et nombre de variables de sécurité dans les différents projet que nous avons étudié. De plus, nous avons fait la distinction entre Java et Go pour comparer leur utilisation des paramètres de haut niveau.
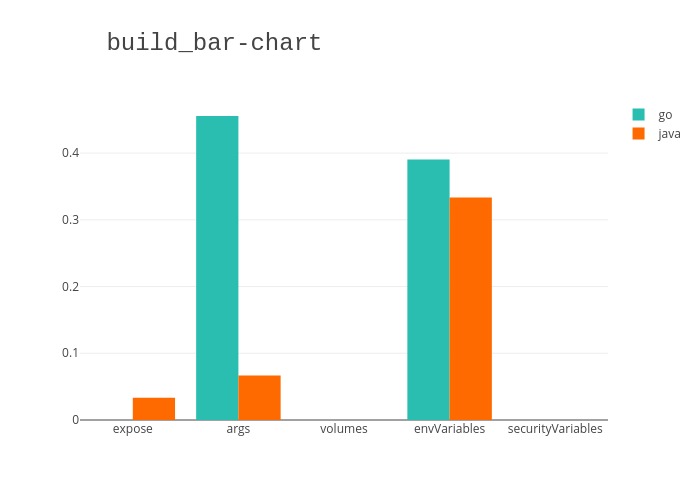
Dans cette phase nous nous attendions à ne pas trouver d’expose car cela n’a pas de sens d’ouvrir un port lors de la construction.
Cependant nous remarquons dans ce schéma qu’une application Java en utilise un. Après avoir verifié manuellement dans le projet concerné, nous avons remarqué qu’il s’agissait d’une anomalie de notre analyseur de dockerfile qui rencontrait 2 primitive FROM l’une après l’autre et les interprète mal.
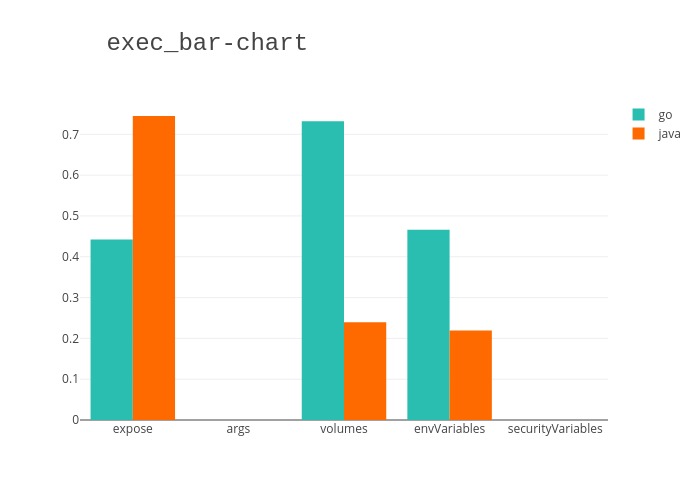
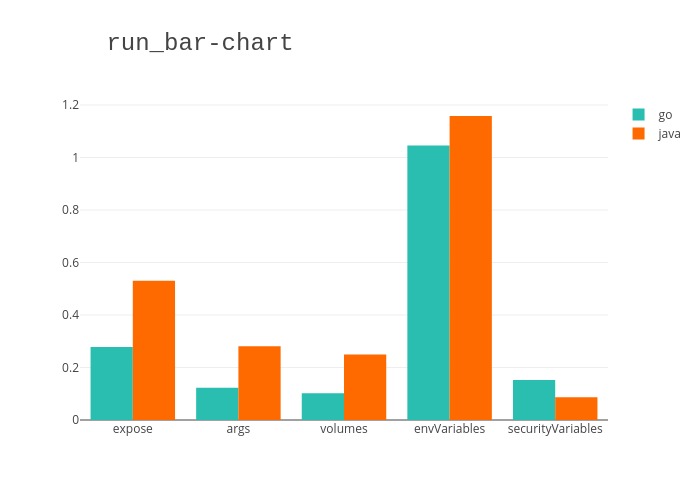
Ensuite dans les graphes suivants nous avons essayé de trouver des corélations entre le nombre d’exposes et le nombre de variables de sécurité déclarées. Nous avons fait le calcul par chaque phase ainsi que pour le global. De plus nous avons de nouveau fait la distinction entre les langages pour les comparer.
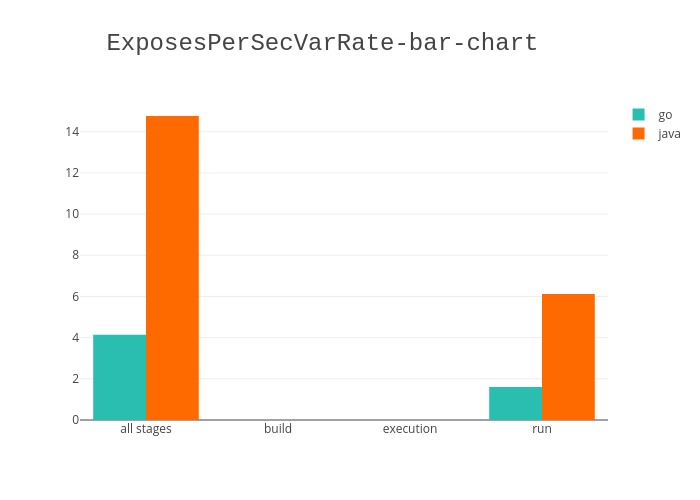
Ici nous pouvons remarquer que même si nous avons des données uniquement pour la phase de run, la relation est différente. Pour toutes les phases en GO nous pouvons compter quatre exposes pour une variable de sécurité alors que dans la phase de run uniquement nous comptons environ deux exposes pour une variable de sécurité. Nous pouvons l’expliquer par le fait qu’il n’y a pas de déclaration de variables de sécurité dans les autres phases. Mais uniquement des exposes ce qui ne permet pas d’établir une corélation dans ces phases. Cependant cela augmente leur nombre total, c’est pourquoi les valeurs sont plus élevées pour la totalités des phases.
Nous avons également analysé les variables d’environnement et de sécurité les plus utilisées dans les deux langages. Si le même nom de variable apparaît dans deux projets différents, nous ajoutons une apparition à cette variable.
Les résultats pour les variables d’environnement de GO ont été:
| Rang | Variable | Apparitions |
|---|---|---|
| 1 | ‘GOPATH’ | 48 |
| 2 | ‘PATH’ | 34 |
| 3 | ‘CGO_ENABLED’ | 9 |
| 4 | ‘DOCKER_HOST’ | 5 |
À partir de ce point, nous trouvons quelques variables avec 2, 3 voir 4 apparitions, mais la majeure partie n’apparaît qu’une seule fois.
Du côté des variables de sécurité, le résultat n’offre rien à remarquer parce chaque variable n’a qu’une seule apparition.
Pour les variables d’environnement de JAVA, leur nombre d’apparition maximal pour une même variable est de deux. Cela ne nous permet pas de déterminer une norme mais de déduire que l’utilisation des variables en java est fortement dépendante du contexte dans lequels il évolue.
En étant les suivantes:
Pour ce qui concerne les variables de sécurité en Java, comme pour GO nous ne pouvons rien remarquer de particulier car nous en trouvons encore moins et toujours en une seul instance. Cela vient, sûrement, du fait que nous avons moitié moins de projet Java que de projet Go ( moins de dockerFile et moins de dockerFile valides, c’est à dire avec au plus deux stages).
Les résultats que nous avons présentés dans la partie précédente sont relativement hétérogènes. En effet, sur certains critères, les langages Java et Go ont de fortes similarités alors que sur d’autres mesures, il y a de fortes disparités.
Par exemple il y a une forte similarité pour l’étape de RUN du Dockerfile, où l’utilisation des paramètres entre Go et Java suit la même tendance. C’est-à-dire que leur taux d’apparition pour les différents types de paramètres sont assez proche.
En revanche pour la phase de build et d’execution, les valeurs sont très différentes.
Nous pouvons faire deux suppositions pour expliquer l’hétérogénéité des variables d’environnement :
Lors de cette étude nous n’avons pas pu vérifier laquelle de ces deux supposition est la plus pertinente étant donné qu’il faudrait analyser “à la main” de très nombreux projets, comprendre l’utilité de chaque paramètre, et estimer (avec quelle précision ?) si des variables au nom différent remplissent ou non la même fonction.
Existe-t-il des liens entre les différents types de paramètres de haut niveau ?
Existe-t-il des points communs de paramètrage entre plusieurs technologies/langages ?
expose par exemple). Pour le reste du paramétrage il n’y a que très peu de points communs.Existe-t-il des corélations entre les différents types de paramètres ?
Pour obtenir tous ces résultats nous avons développé trois scripts en javascript et typescript.
Le premier en javascript pur, utilise l’API de github, il nous sert à récupérer une liste de repository contenant au moins un dockerFile et écrit dans le langage que l’on souhaite analyser (Golang et Java). Pour être sûr de récupérer des projets ayant de la valeur pour notre étude nous avons décidé de les trier en fonction de leur nombre d’étoile. Chaque étoile signifie qu’un utilisateur a souhaité ajouter le projet à ses favoris et y porte de l’intérêt.
Le second script écrit en typescript prend en entrée un fichier contenant la liste des repository interessant pour un language. Pour chaque répository il va vérifier si le DockerFile contient bien au moins la phase de build de l’image et pas plus de 2 phases (compilation du code source et construction de l’image).
Il va ensuite extraire de ce repository des données provenant de différents fichiers :
.sh pour la phase d’instanciation de l’image.Puis il va stocker ces différentes données dans un fichier JSON (1 par repository) afin de pouvoir les conserver pour d’autres utilisations.
Ce script gère les repositories par batch de 10 en parallelisant grâce aux fonctionnalitées de nodeJS les appels systèmes et réseau (clone des répos, appels files systèmes dont lectures des fichiers, etc ..). Afin d’optimiser le temps de traitement, cela nous permet de gérer les 475 repos Golang en une vingtaine de minutes avec une bonne connexion internet à fibre et un disque dur SSD NVMe.
Le troisième script est écrit en typescript. Il génère les graphes en utilisant la bibliothèque plotly et les données obtenues avec le script précédement décrit.
Repo Git du projet, les listes des projets utilisés sont dans les dossiers:
liste des ressources utilisées :