Nous sommes quatre étudiants en dernière année à Polytech Nice Sophia Antipolis, dans la spécialité Architecture Logicielle :
Les dépendances sont un merveilleux moyen de réutiliser des codes existants et obtenir un gain de temps conséquent. Cependant, il est souvent impossible de connaitre la globalité de ces dernières et d’en appréhender leurs qualités à première vue. Nous devenons dépendants de toutes les erreurs persistantes transmisses par les dépendances.
De plus, un projet de taille importante contenant de nombreuses dépendances peut rapidement gagner en complexité. En effet, à cause de ces dernières, un projet devient difficilement contrôlable en terme de complexité.
Est-ce vraiment si facile de réutiliser ces dépendances ? Qu’en est-il de la “qualité” du projet et qu’est-ce alors que cette qualité ?
Nous vous proposons dans ce chapitre de vous présenter une démarche à suivre lors de l’arrivée dans un projet de taille conséquente en tant que développeur, pour mieux l’appréhender. Nous prenons appui sur notre retour d’expérience sur le projet ROCKFlows et ce à quoi nous avons été confrontés à notre arrivée sur ce dernier.
Notre développement se divise en deux parties principales :
La première présente les différentes complexités résultant des dépendances et la seconde introduit notre solution à l’échelle globale du projet et à plus petit grain, pour chaque type de complexité.
ROCKFlows (pour Request your Own and Convenient Knowledge Flows) est un projet de machine learning développé par le laboratoire I3S de Sophia Antipolis. Son objectif principal est de fournir une interface simple d’utilisation à des utilisateurs non-experts en machine learning dans le but de trouver le meilleur workflow leur permettant de classifier au mieux leur ensemble de données. En effet, ROCKFlows ne peut que classifier des données, il n’a pas la possibilité de faire de la régression.
Pour l’utilisateur non-expert, ce produit se base sur le principe de boîte noire : toutes les spécifications liées au domaine du machine learning lui sont cachées, lui permettant de simplement fournir un jeu de données en entrée et de récupérer des résultats compréhensibles en sortie.
Ayant, pour la majorité du groupe, travaillé sur ROCKFlows lors de projets précédents, il nous semblait intéressant d’analyser ce projet plus en détails. Nous avons fait face à cet imposant projet (39 dépôts différents) et il a été difficile de visualiser le projet dans son ensemble. Nous avions donc à cœur d’aider les nouveaux arrivants ainsi que les contributeurs déjà présents sur le projet à avoir une vision plus globale de ROCKFlows.
Plusieurs membres de notre équipe ont réalisé leur projet de fin d’étude en relation avec ROCKFlows. Avant de commencer le développement, nous avons été confrontés à un projet imposant et dans lequel il est difficile d’entrer. Cela nous a donc pris beaucoup de temps avant de nous familiariser avec l’ensemble du projet. Ceci est un problème commun à beaucoup de projets, dès lors qu’ils sont conséquents. Cette complexité était notamment empirée par des dépendances autant internes qu’externes. C’est donc sur cet aspect que nous avons voulu diriger notre étude. L’objectif est d’analyser l’impact des dépendances sur la qualité d’un projet en s’appuyant sur ROCKFlows et nous en sommes donc arrivés à la question suivante :
Les dépendances impactent-elles la qualité du projet ROCKFlows ?
__La qualité peut être exposée par plusieurs métriques comme le “code-smell”, le nombre de bugs, les vulnérabilités du code. Néanmoins, nous ne nous sommes pas attardés sur le pourcentage de couverture des tests puisque ce dernier était trop faible (un seul dépôt contenait des tests).
L’état de fait dans lequel nous trouvions nous a mené à deux parties qu’il nous semblait intéressantes à développer :
L’intérêt principal de notre point de vue est de fournir une aide tant aux développeurs qu’aux nouveaux arrivants. De plus, nous avons eu des retours de développeurs de ROCKFlows rapportant que ce problème est récurrent. Les développeurs déjà présents sur le projet ont seulement connaissance de leur partie du projet et ont rarement une vision globale. De ceci découle notre second problème : les développeurs arrivant sur le projet ne trouvent pas de documentation générale sur le projet étant donné qu’aucun développeur expérimenté sur le projet a la connaissance sur la totalité du projet.
Fournir cet outil permettra donc d’élargir la vision des développeurs sur un projet de taille conséquente, ainsi que fournir un point d’entrée dans le projet pour les nouveaux arrivants.
Un premier type de complexité se situe au niveau des dépendances vers des bibliothèques externes. En effet, ces dernières sont utiles, mais il arrive que différents utilisateurs aient besoin de versions différentes de cette même bibliothèque. Par exemple, dans le cas où une fonctionnalité est présente dans une nouvelle version, un utilisateur arrivant sur le projet va privilégier l’utilisation de cette nouvelle version, sans se soucier si une version antérieure est déjà présente dans le projet. Cet empilement de versions peut mener à des erreurs d’utilisation de la bibliothèque.
Lors de notre analyse de ROCKFlows, nous avons pu observer de nombreuses bibliothèques comptant trois versions ou plus. De plus, il y avait de mauvaises pratiques mises en place dans le projet. Par exemple, toutes les versions des dépendances Docker étaient mises en latest. Cette fonctionnalité entraîne l’utilisation forcée de la dernière version de la bibliothèque. Si cette dernière version contient des modifications sur le comportement interne d’une commande, l’utilisateur n’en aura aucune idée et utilisera donc un commande sans connaitre son comportement.
Ce second problème est plus lié à l’être humain. En effet, le précédent est lié intrinsèquement à l’informatique. A l’inverse, celui-ci est lié à la compréhension humaine du code. Si une interface est mal présentée, avec des noms de fonction qui ne reflètent pas leur rôle, la compréhension de cette interface s’en voit compliquée. Ce type d’incompréhension peut mener à des erreurs d’utilisation de ladite interface.
De nombreuses interfaces présentes dans ROCKFlows présentent ce problème. Les noms des interfaces ne sont pas clairs sur leur rôle, et combinés à l’absence de documentation, rendent la compréhension de leur utilisation très complexe. Il faut donc entrer dans le code pour comprendre le comportement. Ceci est un gros frein lors de la première approche de ROCKFlows.
Dans ce troisième exemple, nous nous intéressons aux dépendances Docker. Les images Docker dépendent d’images parentes. Or il arrive que des dépendances soient présentes à la fois dans l’image fille et dans l’image parente. La dépendance dans la fille est donc inutile. En effet, il existe une transitivité entre les parents et les enfants pour les images Docker. Toute dépendance présente dans l’image parente est transitivement présente dans l’image fille. Il est donc inutile de répéter cette dépendance dans la fille. Ce type de problème arrive souvent car le créateur de l’image fille n’a pas connaissance des dépendances utilisées dans les images parentes.
Lors de notre développement d’images Docker pour ROCKFlows, nous avons rapidement fait face à ce type de problème. En effet, nous n’avions pas accès à certaines images Docker parentes et donc aucun possibilité de connaître les dépendances déjà présentes. Nous avons donc dû ajouter nos dépendances sans savoir si ces dernières étaient déjà présentes dans des images parentes.
Ce dernier problème est le plus classique que nous pouvons rencontrer avec les dépendances entre différents sous-projets au sein d’un projet. Si une erreur est présente dans un sous-projet et que ce dernier est utilisé par un autre sous-projet, l’erreur présente dans le premier sous-projet se propagera au second. Ce type de propagation peut rapidement atteindre la majorité du projet si ce dernier contient un nombre élevé de dépendances entre les sous-projets. Ce type de propagation peut aussi passer par les images Docker.
C’est le cas auquel nous avons fait face lors de notre développement au sein de ROCKFlows. Une image Docker parente contenait une erreur qui empêchait de lancer le traitement de données par ROCKFlows. Or, nous utilisions cette image pour la création d’une seconde image permettant de travailler sur le traitement des images. L’erreur était donc propagée à notre image. Il nous a été très difficile de remonter à la source du problème car nous n’avions pas de connaissance sur la structure du projet.
Nous avons pu voir différents types de problèmes liés aux dépendances. Ces problèmes sont souvent présents dans les projets de grande envergure. Nous avons pu voir que ROCKFlows contient la totalité des problèmes présentés ci-dessus et que nous, en tant que nouveaux développeurs sur le projet, avons fait face à tous ces problèmes en l’espace de 4 semaines de développement sur ce dernier. Ce sont donc des problèmes qui semblent récurrents.
Notre démarche a pour objectif d’aider l’utilisateur à se faire une idée globale d’un projet, pour qu’il puisse mieux l’appréhender. Nous proposons dans un premier temps un script qui, de façon automatique, va analyser l’ensemble des dépôts, à condition qu’ils soient tous dans le même dossier. Nous avons choisi pour cela SonarQube car il supporte plus de vingt-cinq langages (Java, C, C++, Objective-C, C#, PHP, Flex, Groovy, JavaScript, Python, PL/SQL, COBOL…) ce qui permet une grande flexibilité vis à vis des projets. De plus, nous pouvons également exposer les métriques suivantes :
Cette première partie va nous permettre d’exposer les parties critiques du projet suivant les critères listés ci-dessus. Ainsi, le nouvel utilisateur ou développeur peut rapidement avoir un premier aperçu du projet.
Par conséquent, nous avons essayé de faire une analyse du projet ROCKFlows pour voir si les parties centrales, comme le coeur de ROCKFlows, allaient être exposées comme des parties critique ou non. Voici nos résultats (nous n’exposons pas tous les dépôts car certains ne donnent pas de résultat en effet ils ne contiennent que des jeux de données) :
| Nom du dépôt | Quality gate | Bugs | Vulnérabilités | Dettes technique | Code “puant” | Couverture tests | Duplication |
|---|---|---|---|---|---|---|---|
| Workflow-composition | Passé | 3 (E) | A (B) | 4h (A) | 40 (A) | 0% | 0% |
| StatisticAnalyzer | Passé | 1 (E) | 122 (B) | 2j (A) | 87 (A) | 0% | 0% |
| PatternWorkFlow | Passé | 8 (E) | 117 (B) | 2j (A) | 133(A) | 0% | 4% |
| AnalyseIntermediateResults | Passé | 4 (E) | 177 (B) | 2j (A) | 98 (A) | 0% | 14% |
| Tester | Passé | 10(E) | 118 (B) | 2j (A) | 80 (A) | 0% | 0.8% |
| FindDatasets | Passé | 6 (E) | 108 (B) | 2j (A) | 143(A) | 0% | 3.9% |
| Experiments-core | Passé | 4 (C) | 1 (B) | 5h (A) | 35 (A) | 0% | 1.7% |
| Fold-splitter | Passé | 0 (A) | 0 (A) | 11min(A) | 4 (A) | 0% | 0% |
| Experiments (weka-algo) | Passé | 2 (D) | 0 (A) | 4h (A) | 23(A) | 0% | 13.1% |
| dm-experiments | Passé | 15(E) | 167 (B) | 7j (A) | 317(A) | 0% | 13.1% |
| rockflows | Passé | 8 (E) | 16 (B) | 23j (A) | 268(A) | 0% | 11% |
| Prediction | Passé | 3 (E) | 12 (B) | 7h (A) | 116(A) | 2.1% | 0% |
| openML-datasets | Passé | 2 (E) | 8 (B) | 1j (A) | 79 (A) | 0% | 0% |
| experiments-ui-master | Passé | 12(D) | 0 (A) | 1j (A) | 130(A) | 0% | 0.3% |
| Image-Analysis | Passé | 0 (A) | 0 (A) | 2h (A) | 29 (A) | 0% | 0% |
| database-master | Passé | 2 (C) | 1 (E) | 9j (A) | 320(A) | 0% | 7.3% |
| Pipelines-generation | Passé | 2 (E) | 1 (B) | 5h (A) | 38 (A) | 0% | 0% |
| pfe-deep-learning | Passé | 0 (A) | 0 (A) | 1j (A) | 33 (A) | 0% | 30.2% |
| splar | Passé | 57(E) | 36 (B) | 23j (A) | 1.4k(A) | 0% | 6% |
| openML-metrics | Passé | 0 (A) | 4 (B) | 4h (A) | 30 (A) | 0% | 9.2% |
| justifications | Passé | 1 (E) | 0 (A) | 1j (A) | 43 (A) | 0% | 2.2% |
Ainsi, nous pouvons observer qu’il en ressort deux parties critiques qui sont :


Cette première étape dans notre démarche suggère donc aux nouveaux arrivants de commencer par s’intéresser à ces parties car elles sont très probablement des parties importantes du projet notamment dû à la dette technique exposé dans le tableau précédent. Cependant, l’analyse de SonarQube est loin d’être suffisante. En effet, le projet ROCKFlows est confronté au problème “du plat de spaghetti”. Il nous fallait donc corréler la partie de l’analyse faite ci-dessus avec un graphe de dépendance pour confirmer si les deux dépôts sont bel et bien des parties critiques mais également si de nouvelle partie critique émerge dû à leur haute dépendance par exemple au dépôt “rockflow-core” exposé précédemment.
Pour pouvoir visualiser les dépendances au sein d’un projet, nous avons utilisé Pom-Explorer un outil qui permet de visualiser les dépendances entres différents projets Maven. Cet outil nous permet de voir les dépendances sous forme de graphe entre tous les projets Maven aussi bien internes qu’externes. _Cette visualisation n’est utilisable que pour les projets qui ont un nombre de sous-projets _Maven inférieur à environ 80 projets. Au-delà, le graphe est illisible. Le graphe nous permet de filtrer les projets affichés et de les colorer pour une meilleure visibilité.

Pom-Explorer permet également de trouver des problèmes de dépendances qui peuvent survenir lors du développement. En effet, Pom-Explorer permet de trouver les dépendances qui sont utilisées avec des versions multiples. Cet outil permet aussi de trouver les dépendances qui n’ont pas de version spécifiée, ce qui est une mauvaise pratique.
Pom-Explorer ne permet que de voir les dépendances entre projets Maven. De plus Pom-Explorer analyse aussi les sous projets ce qui peut donner un trop grand nombre de projets affichés pour être vraiment utile dans la visualisation.
Pour voir à plus gros grain des dépendances entre différents projets nous avons créé un script Python qui va analyser les Dockerfile des projets et produit un fichier qui va être analysé par un script Javascript qui va produire une visualisation avec des graphes de ces dépendances. Cela nous permet aussi de voir des liens entre projets que nous n’aurions pas pu détecter autrement.
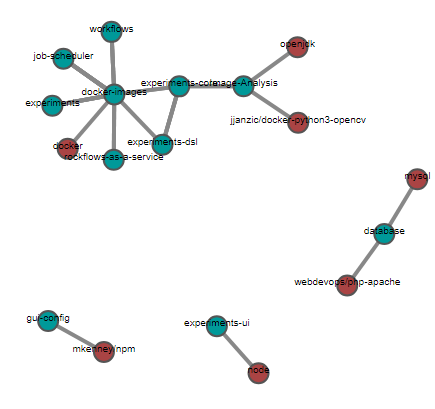
Comme l’on peut le voir sur la figure n°2 les dépendances externes sont en rouge et celles du projet sont en bleu. Ici on a choisi de regrouper les images d’un même dépôt ensemble pour voir les dépendances des dépôts entre eux. Cela nous permet de savoir comment sont organisés les dépôts et avoir une idée générale de l’organisation du projet.
Pour conclure, nous pouvons observer que les résultats obtenus par l’analyse de la complexité et la visualisation des dépendances ne sont pas corrélées pour le projet ROCKFlows. En effet, les sous-projets les plus complexes ont un nombre raisonnable de dépendances. Ils se retrouvent dans la moyenne du nombre de dépendances au sein du projet ROCKFlows. Pour ce qui est des projets contenant de nombreuses dépendances, leur complexité n’est pas parmi les plus élevées.
Cependant, ce résultat se base sur un projet précis (ROCKFlows). Il est donc à mettre en perspective. Il est difficile de tirer des conclusions générales sur les résultats d’un simple projet. Il aurait donc été intéressant d’appliquer notre analyse à d’autres projets de grande envergure pour obtenir plus de résultats.
Nos différents outils nous permettent d’avoir une vision sous différents angles d’un projet aussi imposant que ROCKFlows. Ces derniers sont un atout majeur pour un nouvel arrivant sur un projet. Il aura alors la possibilité de comprendre les connexions entre les différents composants et donc mieux se situer dans le projet.