Février 2018
Nous sommes 4 étudiants à Polytech’ Nice-Sophia specialisés en Architecture Logicielle que voici :
PIX est un projet public de plateforme en ligne d’évaluation et de certification des compétences numériques. C’est un projet en cours de développement qui se veut tout à fait transparent dans la manière dont il évolue. Il s’inscrit dans le cadre de modernisation et d’adaptation des offres du secteur public pour répondre à la croissance exponentielle et inexorable du numérique que l’on constate à la fois pour notre génération et pour les générations futures. Notons par ailleurs que l’acronyme PIX n’en est pas un, et ne signifie rien de particulier mais se veut évidemment évocatif.
Dans sa manière d’être, le projet PIX se présente tel que Agile avec les méthodologies des “Startups d’Etat” et implique de nombreux acteurs allant du ministère de l’Education nationale, de l’Enseignement supérieur et de la Recherche, etc… Il implique aussi différents acteurs du monde professionnel dans une démarche de co-construction. La caractéristique principale du projet, tout du moins dans sa philosophie, qui revient constamment et qui se veut être une véritable pierre angulaire de PIX: l’évolutivité.
Nous allons donc étudier et travailler autour de cette supposée évolutivité afin de pouvoir la remettre en question et de voir comment cela a été mis, ou non, en place. C’est un sujet qui est intéressant sur de nombreux points de vues et c’est pour cela que nous l’avons choisi. En effet nous pouvons discerner dans la politique gouvernementale actuelle un réel souhait de modernisation, d’ouverture, et un désir de se réaliser à travers différents outils et projets liés de près ou de loin à l’informatique, qui est finalement le cadre dans lequel on retrouve le projet PIX. Nous pouvons même associer PIX à deux catégories, la première dûe à sa nature de projet transparent dans son évolution, et la seconde liée à la promesse de réalisation d’une plateforme en ligne d’évaluation et de certification des compétences numériques. En d’autre mots, PIX souhaite aider les élèves et étudiants au niveau de leurs rapports avec l’informatique et sa prédominance dans le monde actuel en renforçant leurs différentes compétences allant de l’utilisabilité aux notions de sécurité.
Nous nous sommes donc demandé comment caractériser cette évolutivité dont se targue PIX. Cette notion d’évolutivité est particulièrement intéressante dans le contexte actuelle où de plus en plus de projet se disant agile et évolutif voient le jour. Les entreprises prennent conscience de la plus value qu’apporte de tels projets. Dans les grands groupes, notamment, on observe un grand nombre de projet de migration d’outil spécifique, utilisant des technologies anciennes vers de nouvelles technologies en suivant les concepts d’agilité et d’évolutivité. Le but de cette démarche étant de concevoir et développer des solutions s’adaptant, autant que faire se peut, aux évolutions des métiers pour lesquels elles sont conçues.
PIX est d’autant plus intéressant pour notre étude car il s’attaque à un domaine en perpétuelle évolution: l’informatique. De plus, il s’adresse à des profils aussi divers que variés. L’évolutivité doit donc faire partie intégrante de sa conception sans quoi ce projet est voué à l’échec. En outre, la transparence dont fait preuve l’équipe qui développe PIX quant au développement de leur produit est un atout non négligeable pour notre étude. En effet, une des premières tâches à laquelle nous nous sommes attelée était l’identification de critères nous permettant de mesurer l’évolutivité d’un projet. Sous notre question générale se cachent donc pas mal de question sous-jacentes tout aussi intéressantes et pertinentes.
Il s’agit tout d’ abord d’étudier, avant de rentrer dans le code, la documentation et la définition de PIX ainsi que ses possibilités fonctionnelles offertes par la version beta de l’application.
PIX se veut, comme on a déjà pu le dire, relativement transparent, et nous avons commencé par étudier le projet de manière très générale, afin de comprendre les tenants et les aboutissants du projet. Le site web du projet, et différents articles présents sur le web ont donc constitué notre source d’informations pour placer le contexte de notre étude, ainsi que d’expliciter la genèse et les objectifs du projet.
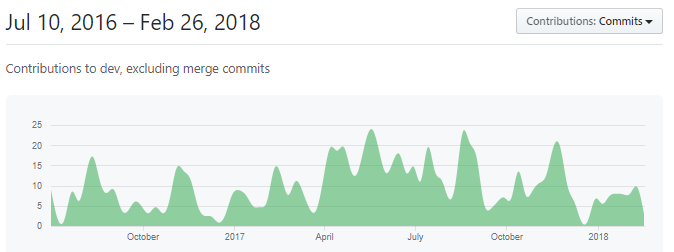
PIX a réellement commencé son développement au milieu de l’année 2016, avec un objectif clair, atteindre les salles de classe pour la rentrée 2017-2018, soit l’année scolaire en cours à l’heure de la rédaction de ce document. Nous verrons par la suite que cet objectif n’a pas réellement été atteint et s’est peut-être révélé être quelques peu optimiste. Nous pouvons en effet voir sur la figure suivante que le développement ne s’est absolument pas arrêté, ni même ralenti sur cette fin d’année 2017. Nous aurions tout à fait pu voir un ralentissement, synonyme de passage de la phase de développement à nouvelle phase de maintenance, mais ce n’est pas le cas (notons que le creux juste avant 2018 est probablement dû à la période des fêtes, comme cela avait été le cas en 2017).
Figure 1 - Contributions sur le repository Github, en terme de commits, depuis le 10 juillet 2016.
Notons tout de même qu’une version beta est disponible et que certains établissement commencent à proposer à des élèves ou étudiants de différentes formation un premier contact avec la plateforme. PIX a revu ses objectifs et vise désormais une généralisation pour la rentrée 2018-2019, avec on peut se permettre de le supposer, une poussée ministérielle et probablement des moyens de mise en production et de mise en place accrus.
De par sa méthode de conceptionAgile, PIX a été rapidement utilisable à travers unMinimum Viable Productqui a su évoluer. Nous sommes ici en plein coeur de cette méthode de conception qui consiste à livrer de la valeur continuellement, en évitant au maximum les rétrogradations, PIX a donc rapidement été testable par des utilisateurs. Et c’est ici aussi que nous retrouvons la démarche de co-conception vantée par le projet, PIX s’est confronté à des utilisateurs tests toutes les 2 semaines (ce qui correspond probablement à la période supposée desprint agile) afin d’intégrer ces derniers au coeur du processus et livrer quelque chose correspondant, au moins sur l’expérience utilisateur, aux attentes.
Le deuxième point à aborder est évidemment le côté co-construction, mais du côté code cette fois ci, bien évidemment c’est un point que nous approfondirons plus en détails au fil de cette étude. Ce projet est donc ouvert sur Github et a été élaboré par 16 contributeurs différents. Ces contributions sont cependant bien différentes, et malgré un ordonnancement et une norme précise au niveau des descriptions des commits, les apports sont assez hétérogènes et tous n’ont très clairement pas participé à la même auteur. C’est cependant une caractéristique tout à fait normal dans un projet ouvert. Il est néanmoins difficile de comparer ce projet à des projets tout à fait Open Source qui regroupent eux plusieurs dizaines, voire centaines, de contributeurs (avec évidemment aussi des contributions hétéroclytes). Il est finalement assez complexe de classer la méthode de conception, car elle n’est pas réellement Open Source, nous ne pouvons en effet contribuer facilement au projet, mais n’est pas non plus réellement privée, puisque le code est en accès libre, et chacun peut l’utiliser (ou le forker).
Malgré tout, ce projet est soumis aux desideratas d’entités hiérarchiquement supérieures aux développeurs, puisque le mandataire n’est évidemment autre que le ministère de l’enseignement, et ce malgré les revendications contraires qui cherchent parfois à potentiellement masquer ceci. L’objectif étant comme on a pu le dire, de remplacer les B2I, C2I, et autres certifications légales informatiques qui n’ont plus de réelle valeur dans le monde volatil d’aujourd’hui, et même si cette fois la finalité ne sera pas “certification ou non-certification” mais sera un score ou une grille de score pour échelonner les résultats, les contraintes “légales” sont quand même là. Les Français doivent en effet pouvoir répondre aux attentes, et ces attentes doivent aussi être suffisamment élevées pour qu’elles fassent sens par rapport à l’informatique de nos jours.
PIX est donc la toute nouvelle plateforme pour faire passer des certifications d’aptitudes à l’utilisation de l’informatique et la connaissance des compétences numérique. Mais aussi pour s’exercer et découvrir l’informatique plus en profondeur, à travers un niveau et une difficulté qui s’ajustent selon le profil utilisateur. En effet, chaque utilisateur aura un compte unique, à priori ouvert à vie, qui sera créé par exemple en milieu de collège. Son expérience utilisateur sera ensuite adaptée sur l’ensemble de la plateforme.
L’objectif affiché est donc de totalement remplacer les outils et certifications en place qui se révèlent être tout à fait obsolètes, principalement le B2I et le C2I (respectivement “brevet informatique et internet” et “certificat informatique et internet”). Ces objectifs s’atteindront à travers une évolutivité fonctionnelle comme le présente un porteur du projet:“Les 600 à 700 acquis mesurés via les épreuves sont faits pour s’adapter au fil des évolutions des technologies et de la société. On s’est adossé à un référentiel de compétences européen, le DIGCOMP. À chaque fois que ce référentiel changera, on mettra Pix à jour.”. PIX aura donc appris de ses prédécesseurs et se présente vraiment comme novateur à tous les étages.
L’évaluation se fait sur huit niveaux dans seize compétences. Elles sont réparties en cinq grands domaines : information et données, communication et collaboration, création de contenu, protection et sécurité, environnement numérique. Les exercices sont très diversifiées et présentent des interactions beaucoup plus poussées, on retrouve par exemple des questions de recherche demandant de retrouver sur des sites annexes comme Wikipédia l’historique d’une modification, ou encore de créer des graphiques Excel ou OpenOffice à partir de feuilles de données téléchargeables. L’accent a été mis sur le fait de rendre toutes les questions accessibles à tous indépendamment du système d’exploitation ou des suites logicielles utilisées, ce qui est aussi un point fort et nouveau du projet.
L’évolutivité est la capacité d’un système à grandir pour répondre à des demandes à venir. Cette évolutivité peut être décrite sous différents aspects pour différents buts. Tout d’abord, l’architecture doit pouvoir gérer et indiquer comment le système prendra en compte une augmentation des exigences en termes de débit et à répondre aux besoins de réduire les temps d’attente par exemple. Cette capacité à monter en charge est une première définition d’évolutivité pour un logiciel.
L’évolutivité peut aussi désigner la capacité d’une application à subir des évolutions fonctionnelles rapidement, au moindre coût, de manière rapide et fiable, c’est-à-dire sans régression des fonctionnalités déjà présentes aussi bien au niveau de leurs fiabilités que de leurs performances.
Afin de répondre à notre problématique, pour notre cas, nous avons décidé de définir l’évolutivité comme suite : s’assurer que l’architecture et l’implémentation sont en concordance l’un avec l’autre tout en leur permettant d’évoluer indépendamment est un critère qui définit si un projet est évolutif.
Pour notre expérimentation, nous avons donc posées les hypothèses suivantes, un projet évolutif doit être synonyme de :
Le caractère public du projet PIX nous a permis d’accéder à plusieurs outils d’analyse d’emblée. En analysant le répertoire Git du projet on a pu se rendre compte que le projet était modulaire, qu’il utilisait des outils permettant de suivre sa couverture de test et de le build automatiquement. En outre, le projet paraissait être bien suivis avec 122 issues ouvertes au moment de notre analyse. Les outils intégrés sur la plateforme Git ont été particulièrement utile puisqu’on a également pu s’apercevoir qu’une branche était créée pour chaque issue en cours de résolution. Enfin, les tags des différentes versions indiquent une livraison en continue à un rythme régulier. Nous avons été agréablement surpris par tous ces indicateurs positifs qui semblent aller dans le sens des hypothèses une, trois, quatre et cinq.
Dans l’espoir de confirmer ces découvertes encourageante, nous avons donc décidé de pousser notre analyse un peu plus loins. Pour ce faire nous avons utilisé les outils CodeCity, CodeScene et RepoDriller dont l’utilisation est explicitée plus bas. Ces outils ont contrasté notre vision, nous nous sommes ainsi rendu compte que certaines branches ont des durées de vie élevées (jusqu’à plus d’un mois) or le risque de livraison croît avec la durée de vie d’une branche.
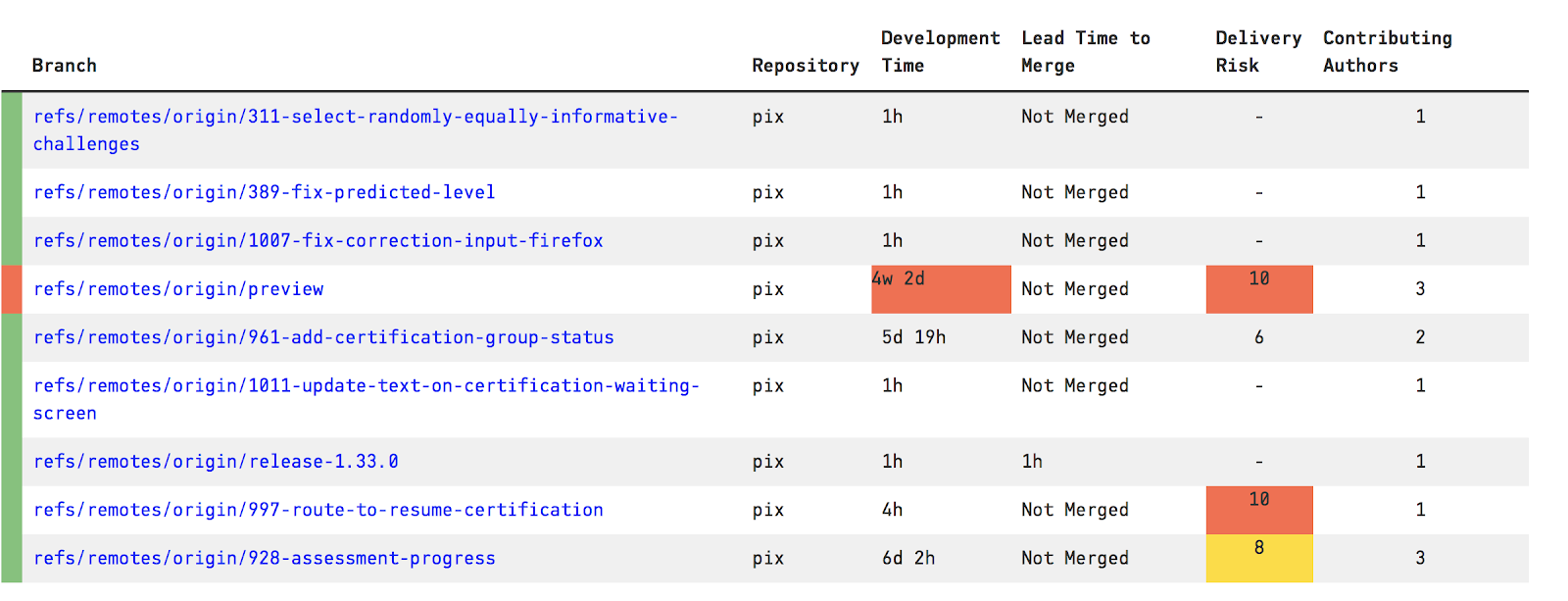
En utilisant CodeScene et RepoDriller, on a aussi pu identifier d’autres points qui paraissaient contraires aux hypothèses que nous avions posés.
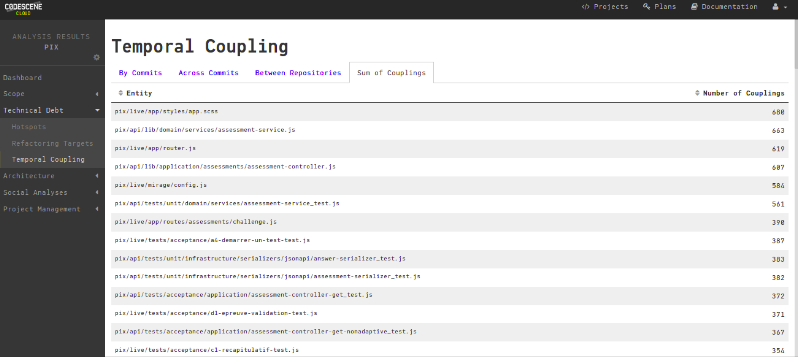 Figure 5 - Couplage temporel de différentes composants du système
Figure 5 - Couplage temporel de différentes composants du système
On a notamment, identifié un fort couplage de fichier nommés assessment-*.js. On peut d’ailleur voire sur l’autre schéma sur le couplage temporel (présenté dans la partie suivante) que ces fichiers semblent être un véritable goulot d’étranglement des qu’ils doivent être modifié. Parmis les autres points négatifs, on a trouvé un faible nombre de collaborateurs actifs, une complexité exponentielle des fichiers de test (observable sur le schéma extrait de CodeCity dans la partie suivante) et des variations de complexité pour le moins étrange.
Nous sommes donc partie sur cette hypothèse pour faire l’analyse et en tirer une conclusion sur si oui PIX respecte ce critère, et dans le cas contraire, si non, pourquoi il ne le respecte pas.
De multitudes d’outils nous ont permis d’enquêter sur l’architecture globale du projet et sur l’organisation des différentes parties impliquées. Nous avons utilisé des outils tels que CodeCity, RepoDriller ou d’autres consorts pour l’analyse de code et l’analyse du repository. L’objectif étant dans un premier temps de se faire un avis global, cela a révélé très rapidement certains points que nous avons étudié par la suite, tel qu’un couplage très fort entre 2 parties du code qui se trouve être relativement massives et qui semblent dans un premier temps être un véritable frein à la philosophie “évolutive” du projet.
Bien évidemment, notre première approche était resté très globale et relativement superficielle. Il reste néanmoins intéressant de noter que de potentiels pistes se sont révélées très rapidement avec des analyses utilisant les paramètres “de base” de certains outils, nul doute quant aux potentialités d’analyses poussées avec les différents outils d’analyse de code et de repository.
Nous avons donc procédé à cette phase de tests poussées notamment principalement avec les outils CodeCity et CodeScene tout en comparant le projet PIX avec d’autre projets du même type et qui partagent la même philosophie de développement. Ces deux outils utilisent donc les bases de code disponibles via Git pour analyser les projet selon différents aspects qui sont principalement la modularité, la complexité et d’autres éléments comme la duplication de code ou bien le pourcentage de refactoring et le pourcentage de dette technique accumulé par exemple.
Pour l’utilisation de CodeScene, on commence par “fork”le GitHub du repository qu’on veut analyser sur notre propre compte c’est-à-dire dans notre propre repository. On connecte ensuite notre repository à CodeScene ce qui va nous permettre d’importer le projet visé dans l’outil. Une fois le projet importé, on lance la phase de test et d’analyse. Suite à cela, nous allons avoir différents métriques sur le projet dans sa globalité et ils nous restera plus qu’à faire des constats et retenir les informations pertinentes utile pour répondre à notre problématique. On peut grâce à cet outil faire des analyses en détail classe par classe et constater les différents problème auquel le projet fait face. Cette phase d’analyse via CodeScene à été faite également sur d’autre projet afin d’avoir des éléments de comparaison et appuyer nos arguments sur les différents constat qu’on a pu établir en ce qui concerne si PIX est évolutif ou pas. CodeScene va nous renseigner sur l’évolution du code. Cela nous donnera la possibilité de prédire son avenir et de trouver le code qui est difficile à développer et sujettes à des défauts.
Après connexion de notre compte et l’importation des projets dans CodeScene nous obtenons le panneau suivant avec les différents projets analysable :

Figure 6 - Vue de l’outil CodeScene
On peut donc procéder à l’analyse de l’un des projets, ce qui va nous diriger vers le dashboard général récapitulant les informations générales :

Figure 7 - Vue de l’outil CodeScene
Nous avons, à partir de la, accès à l’ensemble du menu qui nous permet d’approfondir notre analyse. Nous avons à disposition différentes rubriques pour pouvoir se focaliser sur un aspect précis :
Figure 8 - Vues de l’outil CodeScene
Nous pouvons donc nous focaliser pour analyser la complexité fichier par fichier ou bien le couplage entre les différents classes du projet. Il ne reste plus qu’à bien structurer nos processus d’investigation afin d’en extraire le maximum d’information rentable :
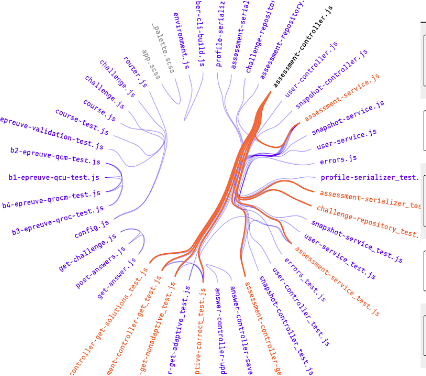
Figure 9 - Couplage interclasses
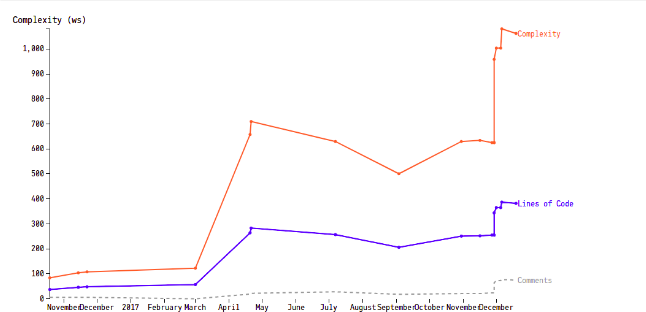
Figure 10 - Complexité temporelle d’une classe extraite du système
Nous avons par exemple après exécution de CodeCity sur le projet PIX (respectivement JSCity puisque c’est le langage principal du projet), la représentation suivante : Figure 11 - JSCity (CodeCity) sur l’ensemble du projet PIX
Figure 11 - JSCity (CodeCity) sur l’ensemble du projet PIX
CodeCity nous permet d’analyser des logiciels, dans lequel les projets sont visualisés en tant que des villes en 3D. C’est un outils clé dans notre analyse de PIX dans la mesure ou on peut constater, selon la forme de la ville, la complexité et la modularité du projet qui sont deux éléments clé dans l’étude de l’évolutivité. Les classes sont représentées comme des bâtiments dans la ville, tandis que les paquets sont représentés comme les districts dans lesquels les bâtiments résident. La hauteur des bâtiment est mappé sur le nombre de méthodes pour une classe en question et le nombre d’attributs sur la taille de base. Le niveau d’imbrication d’un paquet quand à elle est mappé sur la saturation des couleurs du quartier, c’est-à-dire que les paquets profondément imbriqués sont colorés en bleu foncé, tandis que les paquets peu profonds sont en bleu clair. Pour son utilisation, rien de plus simple. Il suffit de cloner le repository que nous voulons investiguer sur notre ordinateur et lancer le programme CodeCity avec la source le chemin du projet en question. Pour une analyse plus poussé, CodeCity nous propose de multitude option qui peuvent nous permettre d’approfondir les résultats si nécessaire.
Nous avons egalement CodeClimate qui nous renseigne sur la qualité du code en intégrant des données de couverture de test et de maintenabilité. Il s’utilise comme CodeScene via GitHub. Nous obtenons ainsi des informations sur le statut global du projet notamment le nombre de duplication présente, le pourcentage de “code smells” et l’analyse de la dette technique.
Tout au long de cette phase d’analyse, nous avons pu conclure sur des faits qui vont nous permettre de répondre si, pour nous, PIX est bien évolutif et s’il ne l’est pas, quelles en sont les raisons.
Pour commencer nous pouvons noter que PIX regroupe de nombreux points positifs. En effet, comme énoncé plus haut nous avons un projet modulaire, bien découpé, ce qui est un élément clé lorsque l’on veut faire un projet dit évolutif. Le suivi de projet, avec 122 issues, est bien traité et maintenue. Le système de build automatique en place devrait permettre de faciliter la tâche des développeurs et permettre de s’assurer qu’une version stable du projet est toujours disponible. La couverture de code est très bonne et elle est supérieur à 95%, ce qui est confirmé par CodeClimate qui indique bien que le projet est maintenable et bien testé. Nous avons à première vu un projet qui se porte bien et qui est bien guidé.
Nous avons notamment un développement constant, avec une branche par issue ou parfeaturece qui annonce une méthodologie de développement plutôt propre et maitrisé. Et pour terminer sur les points positifs, nous avons une équipe qui fait une livraison continue et constante. On pourrait alors conclure rapidement que le projetest bien mené et correspond aux attentes d’un projet ouvert, évolutif, développer en suivant les préceptes de la méthodologie agile.
Mais notre but n’était pas de faire ressortir les points positif mais bel et bien de s’assurer de l’évolutivité du projet, en utilisant un processus répétables comme l’exige toutes bonnes méthodes scientifiques. Par conséquent, nous avons creusé d’avantage, rapidement nous nous sommes aperçus que certaines branches à haute durée de vie ce qui est problématique pour une livraison car on introduit alors un effet tunnel.
Nous avons également de gros refactoring ce qui implique surement une grosse dette technique accumulé dont l’équipe essaye de se défaire ce qui est en soit une bonne chose mais ici nous constatons que ce n’est pas forcément un dette maîtrisé du fait que la complexité ne baisse pas autant qu’espéré. Nous observons aussi des suppressions de code douteuses, nous avons par exemple retrouver un commit intitulé “Suppression de tests en erreur”, ce qui remet en cause la qualité de certains ajouts de fonctionnalités, la gestion de la dette et pire encore l’intégrité de certains morceaux de code.
Nous trouvons en relation surement du problème précédent, beaucoup de duplication de code. Ici nous avons notre outils qui nous indique 62 code dupliqué au sein du projet, ce qui n’est pas dans l’optique du développement évolutif. Si le code dupliqué doit évoluer, nous aurons alors énormément de modification à faire et on risque d’introduire des erreurs plus facilement. Pareillement, si le code dupliqué comporte des erreurs, la correction va impliquer une multitude de modification. Ce procédé ne va pas de pair avec les concepts de maintenabilité et évolutivité.
On peut clairement voir via nos différents outils d’analyse, un très fort couplage entre différentes parties du code, ce qui est un très gros frein à l’évolutivité. On ne peut se permettre d’avoir un fort couplage si le code est amené à évoluer. Il ne faut surtout pas tomber dans l’anti pattern du plat de spaghetti. On a alors des composants logiciel difficilement réutilisable et testable. On peut également faire le constat qu’il y a un “bad smell”au niveau des tests. En effet, on peut constater que nous avons de gros fichier de test, qui induit une très grosse complexité et couplage dans le projet.
Finalement, à travers certains critères, il est possible de caractériser et de mesurer approximativement l’évolutivité d’une base de code. Il est cependant très important de préciser que ces métriques et autres mesures forment une base de connaissances empiriques autour d’un projet, mais pas forcément d’une grande précision. L’évolutivité dépend énormément du cadre métier, des contraintes du projet, de la manière dont il est réalisé et aussi de ses objectifs, et finalement tout un ensemble d’autres critères. Il faut donc, afin d’être le plus objectif possible, adapter ces critères au projet que l’on souhaite évaluer et à son environnement. Dans le cas de PIX, certains freins semblent se poser à une réelle évolutivité tant vantée, la connaissance par exemple n’est pas nécessairement partagée équitablement, et certains choix d’implémentations sont discutables.
Cependant l’évolutivité d’un point de vue fonctionnel est par exemple respecté selon leurs critères, puisque la base des questions et exercices est facilement modifiable et devra suivre une base européenne régulièrement mise à jour. PIX pallie ainsi aux principales faiblesses des B2I et C2I actuellement en vigueur, qui étaient liées à une obsolescence avérée. Concrètement, et on peut associer et retrouver quelques analogies avec la dette technique, puisque cette évolutivité dépend énormément des ambitions du projet et de son environnement, et se caractérise donc de manière propre au sujet d’étude.